神经⽹络可以计算任何函数的可视化证明 #

本章其实和前面章节的关联性不大,所以大可将本章作为小短文来阅读,当然基本的深度学习基础还是要有的。
主要介绍了神经⽹络拥有的⼀种普遍性,比如说不管目标函数是怎样的,神经网络总是能够对任何可能的输入$x$,其值$f(x)$(或者说近似值)是网络的输出,哪怕是多输入和多输出也是如此,我们大可直接得出一个结论:
不论我们想要计算什么样的函数,我们都确信存在⼀个神经⽹络(多层)可以计算它
试想以下这种普遍性代表着什么,我觉得代表着做更多可能的事情(将其看做计算一种函数):
- 比如将中文翻译成英文
- 比如根据⼀个mp4视频⽂件⽣成⼀个描述电影情节并讨论表演质量的问题
- …
现实往往是残酷的,我们知道有这个网络存在,比如中文翻译成英文的网络,通常情况下想得往往不可得,网络在那里,但更可能我们得不到,怎么办?
前面我们知道,我们通过学习算法来拟合函数,学习算法和普遍性的结合是⼀种有趣的混合,直到现在,本书⼀直是着重谈学习算法,到了本章,我们来看看普遍性,看看它究竟意味着什么。
两个预先声明 #
在解释为何普遍性定理成⽴前,关于神经⽹络可以计算任何函数有两个预先声明需要注意一下:
- 这句话不是说⼀个⽹络可以被⽤来准确地计算任何函数,而是说,我们可以获得尽可能好的⼀个近似,通过增加隐藏元的数量,我们可以提升近似的精度,同时对于目标精度,我们需要确定精度范围:$|g(x)-f(x)|<\epsilon$,其中$\epsilon>0$
- 按照上⾯的⽅式近似的函数类其实是连续函数,如果函数不是连续的,也就是会有突然、极陡的跳跃,那么⼀般来说⽆法使⽤⼀个神经⽹络进⾏近似,这并不意外,因为神经⽹络计算的就是输⼊的连续函数
普遍性定理的表述:包含⼀个隐藏层的神经⽹络可以被⽤来按照任意给定的精度来近似任何连续函数
接下来的内容会使⽤有两个隐藏层的⽹络来证明这个结果的弱化版本,在问题中会简要介绍如何通过⼀些微调把这个解释适应于只使⽤⼀个隐藏层的⽹络并给出证明。
一个输入和一个输出的普遍性 #
先从一个简单的函数$f(x)$(即只有一个输入和一个输出)开始,我们将利用神经网络来近似这个连续函数:
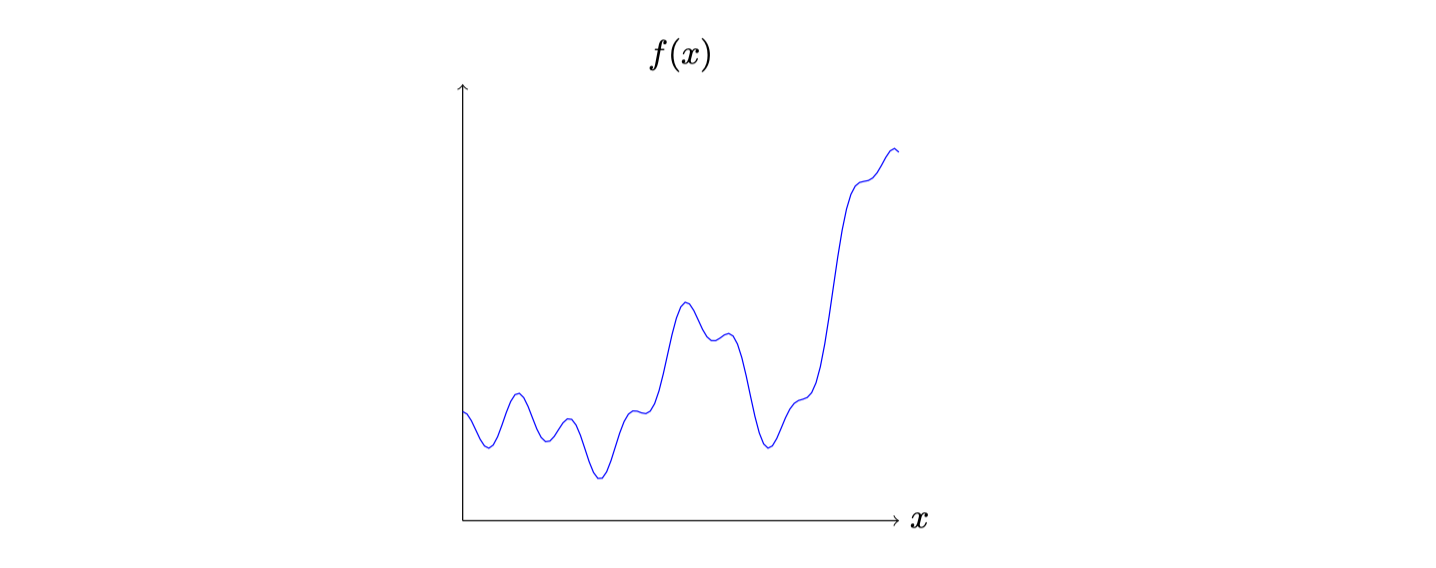
第一章我们就探讨过多层感知机实现异或,这次同样的,我们加入一个隐藏层就可以让函数舞动起来,比如下面这个有一个隐藏层、两个隐藏神经元的网络:
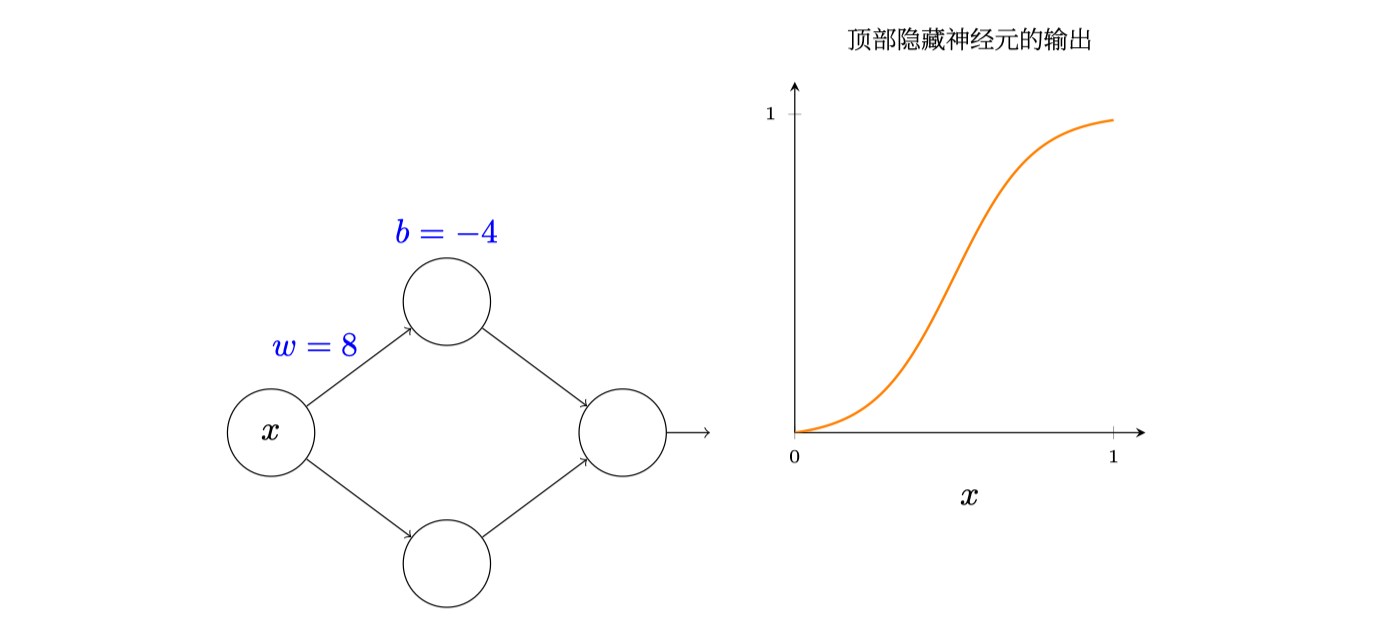
第一步,暂时只考虑顶层的神经元,第一章也讲过S型神经元,所以输出范围类似上图右上角,重点看看这个S型函数,前面已经说过:
$$ \sigma(z) \equiv 1 /\left(1+e^{-z}\right) $$
其中:$z=wx+b$,参见右上角的图,让我们考虑一下几个情况:
- 当$x$不变,$b$逐渐增加的情况下,输出会在原来的基础上变大,图像会相对向左边运动,因为$w$没变,所以图像形状不会变
- 上述情况让$b$键减小,图像会右移,同样图像形状不变
- 当$b$不变,$w$减小,很显然,图像的
陡峭程度会下降,反之亦然
下图是书中给出的图示:
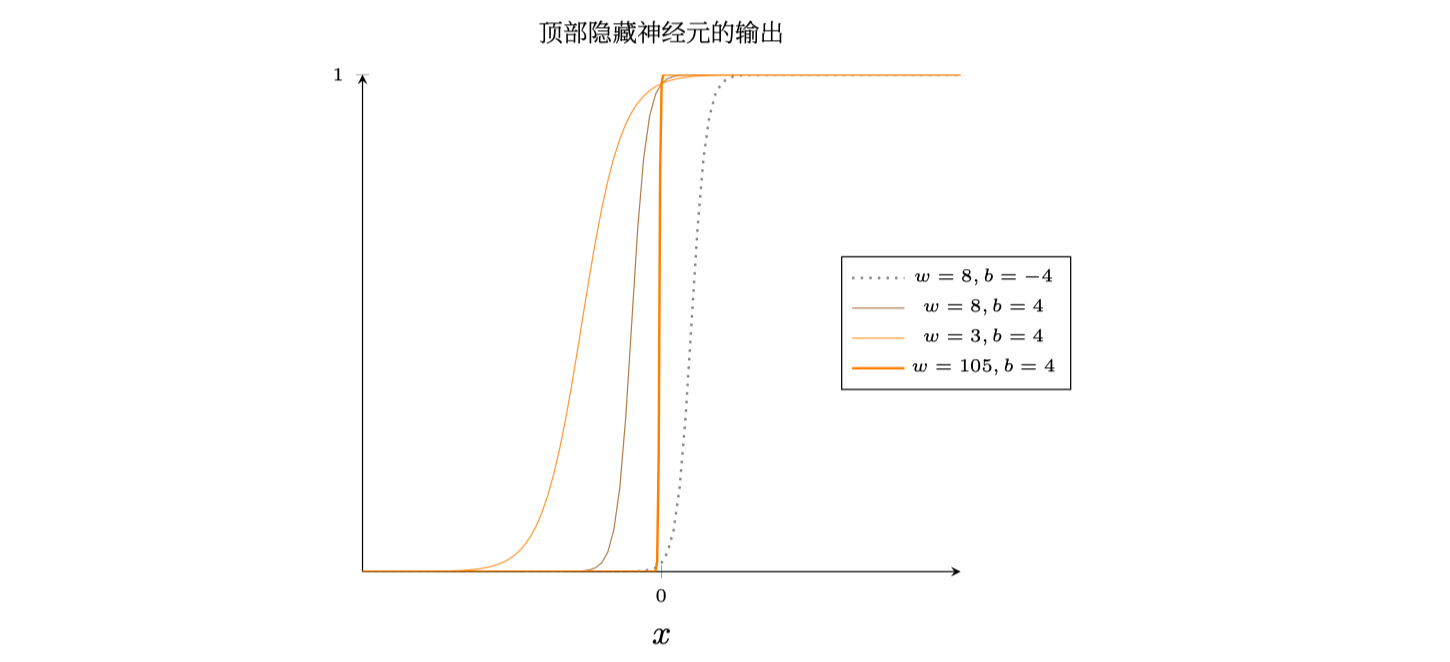
其实我们完全可以自己绘制这个过程,利用Python的matplotlib可以很好地完成这个事情:
import matplotlib.pyplot as plt
import numpy as np
def sigmoid(w, b, x):
return 1.0 / (1.0 + np.exp(-(w * x + b)))
def plot_sigmoid(w, b):
x = np.arange(-2, 2, 0.1)
y = sigmoid(w, b, x)
plt.plot(x, y)
先看下$b$增减下图像的移动情况:
plt.figure(12)
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.subplot(221)
# 绘制原始图像
plt.title("w = 8 b = -4")
w, b = 8, -4
plot_sigmoid(w, b)
plt.subplot(222)
# b增加的图像
plt.title("w = 8 b = 4")
w, b = 8, 4
plot_sigmoid(w, b)
plt.subplot(223)
plt.title("w = 8 b = 4")
w, b = 8, 4
plot_sigmoid(w, b)
plt.subplot(224)
# b减小的图像
plt.title("w = 8 b = 1")
w, b = 8, 1
plot_sigmoid(w, b)
plt.show()
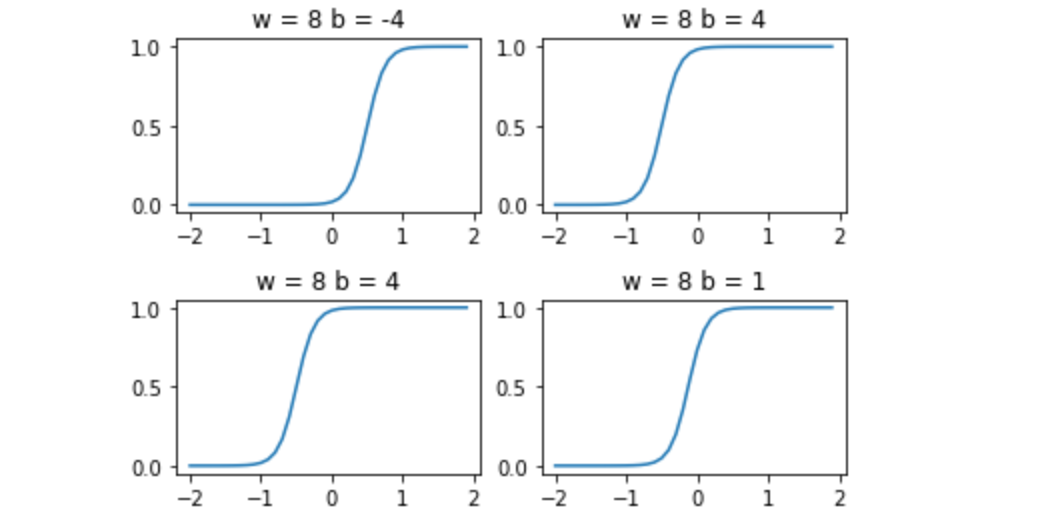
再看下$w$增减下图像的伸缩情况:
plt.figure(12)
plt.subplots_adjust(wspace=0.2, hspace=0.5)
plt.subplot(221)
# 绘制原始图像
plt.title("w = 8 b = 4")
w, b = 8, 4
plot_sigmoid(w, b)
plt.subplot(222)
# w减小的图像
plt.title("w = 3 b = 4")
w, b = 3, 4
plot_sigmoid(w, b)
plt.subplot(223)
plt.title("w = 3 b = 4")
w, b = 3, 4
plot_sigmoid(w, b)
plt.subplot(224)
# w增加的图像
plt.title("w = 105 b = 4")
w, b = 105, 4
plot_sigmoid(w, b)
plt.show()
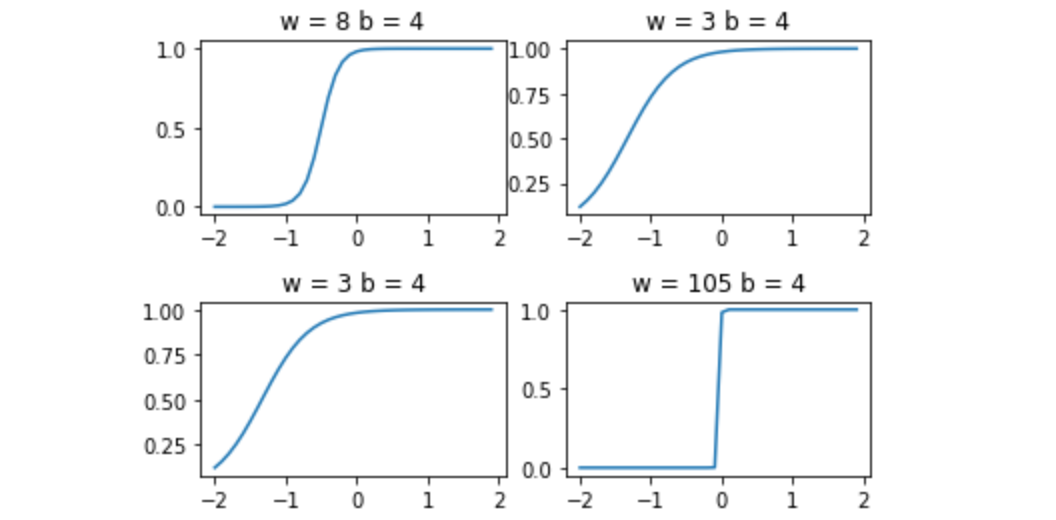
首先通过这两张图验证了上面的三点结论,最后可以看到我们得到的图像就像是一个阶跃函数
为什么需要千方百计地引出阶跃函数出来,这是因为在输出层我们在将所有隐藏神经元的贡献值叠加在一起的时候,分析阶跃函数比S型函数容易。我们该怎么做?结合前面的经验,只要将$w$设置成一个比较大的值,然后通过修改$b$就可以左右移动来定义阶跃函数的位置
思考下,阶跃发生的点在哪?让我们令$wx+b=0$,即可得出阶跃发生的点可以用$s=-b/w$进行表示,现在我们就可以使用$s$来极大简化我们描述神经元的方式
目前为止我们专注于仅仅从顶部隐藏神经元输出,让我们看看整个网络的行为,尤其,我们假设隐藏神经元在计算以阶跃点$s_1$(顶部神经元)和$s_2$(底部神经元参数化的阶跃函数,它们各自有输出权重$w_1$和$w_2$:
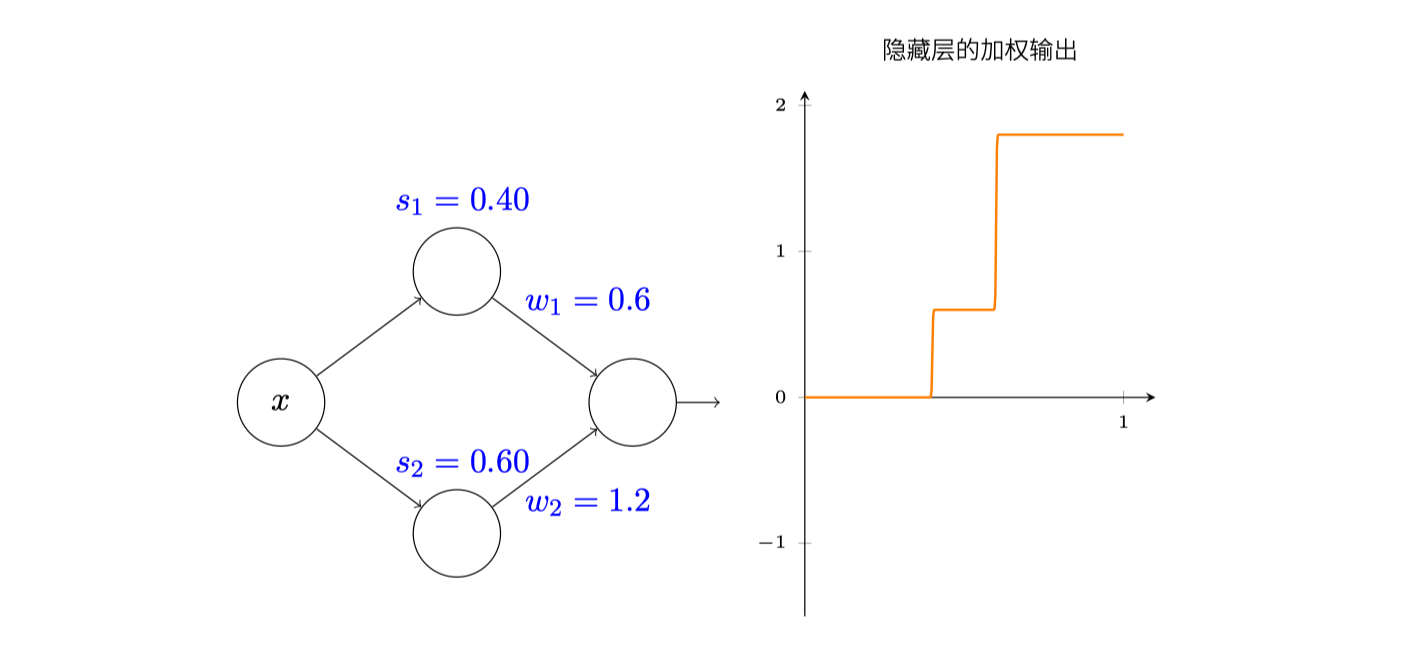
为何隐藏层的加权输出如上图,这理解一下,隐藏层的两个神经元的输出可以想象成阶跃函数,那么:
- x小于
0.4,输出肯定是0 - x大于
0.6,输出就是1.8 - x介于两者之间,输出就是
0.6
接下来,我们进行这样一个设置:
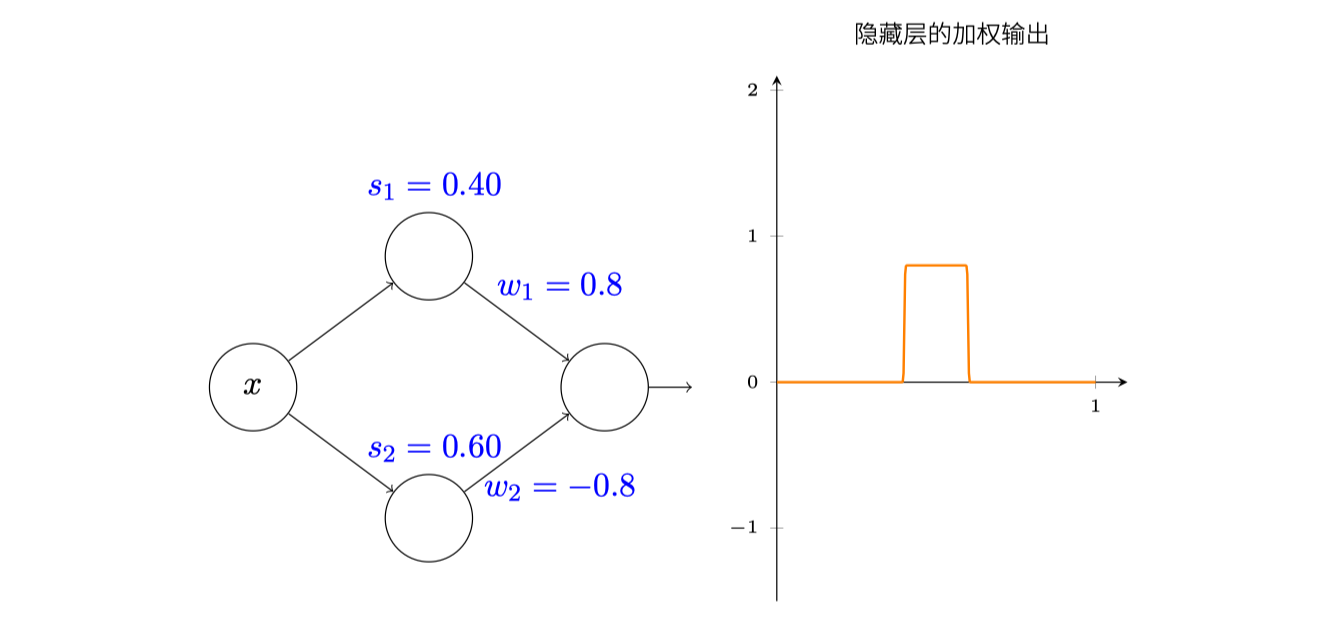
说明一下:
- x小于
0.4,输出肯定是0 - x大于
0.6,输出还是0 - x介于两者之间,输出就是
0.8
这边主要得出的一个结论是,我们可以通过$w_1,w_2$来定义加权输出图像中凸起的位置和高度,为了减少混乱,用一个参数$h$表示高度:
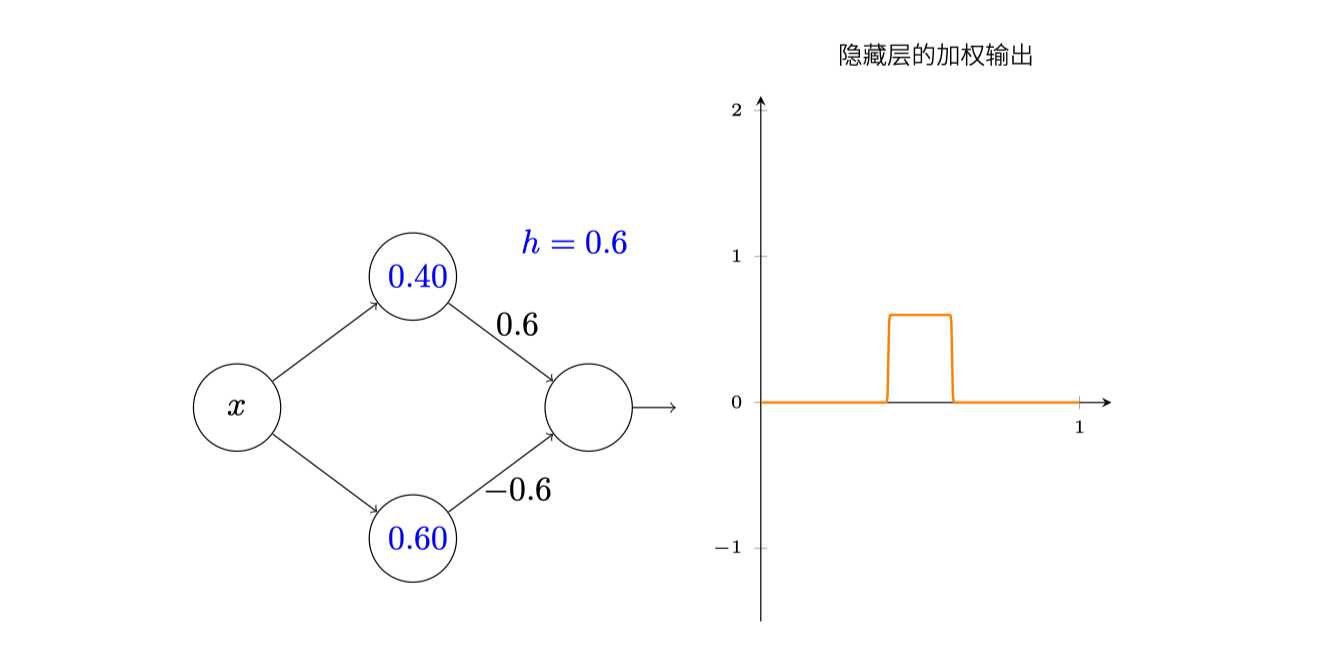
现在我们脑中应该有个清晰的概念,那就是对于神经元的加权输出组合$\sum_{j} w_{j} a_{j}$,我们可以通过对$s$和$h$的调整来控制输出函数,从而让加权输出变成我们心目中的输出
好了,说明结束,接下来看看最开始绘制出来而函数:
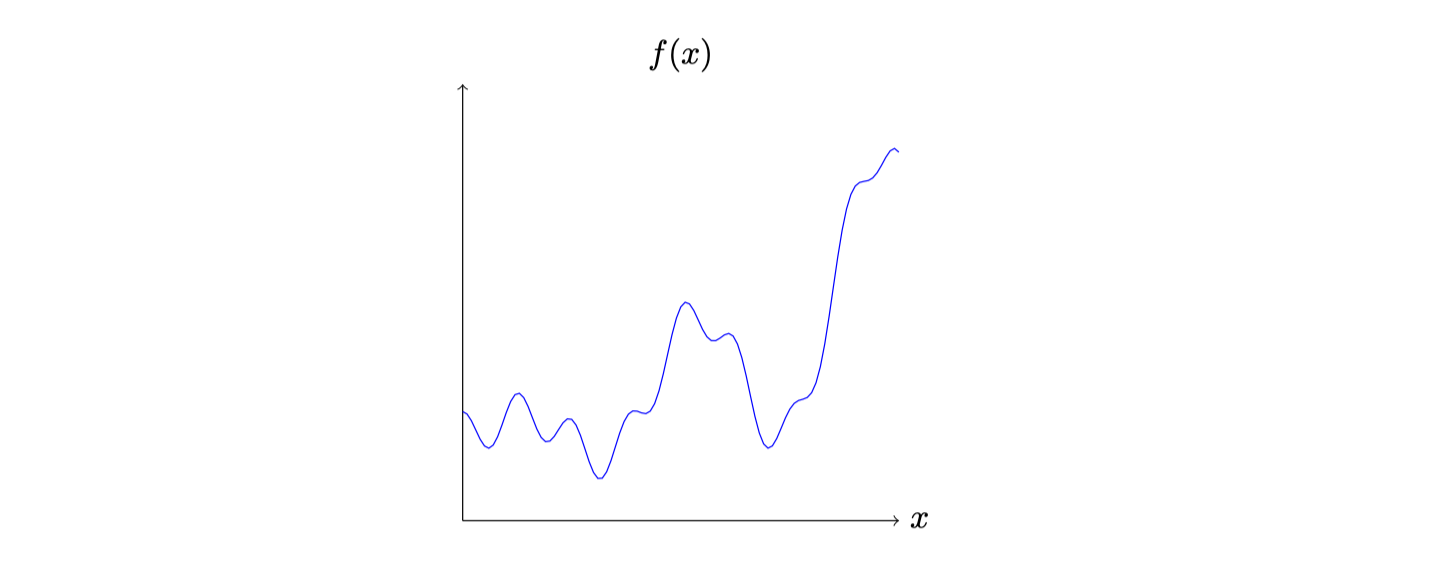
这个函数的表达式为:
$$ f(x)=0.2+0.4 x^{2}+0.3 x \sin (15 x)+0.05 \cos (50 x) $$
现在面临的问题是使用一个神经网络来计算它,前面我们着重分析了隐藏神经元输出的加权组合$\sum_{j} w_{j} a_{j}$,但是要注意,虽然我们经过参数的调整,得到了我们想要的目标函数,此时这个函数是隐藏神经元输出的加权组合$\sum_{j} w_{j} a_{j}$,但是实际上网络的输出是:$\sigma(\sum_{j} w_{j} a_{j}+b)$,也就是说:
- 第一步:我们将隐藏神经元的加权组合$\sum_{j} w_{j} a_{j}$近似成了$f(x)$
- 第二步:但是神经网络的输出却是$\sigma(f(x))$
$\sigma(f(x))$的函数输出和$f(x)$的函数输出那可是大相径庭
我们控制住了隐藏神经元输出的加权组合$\sum_{j} w_{j} a_{j}$,但是没有控制住网络的输出是:$\sigma(\sum_{j} w_{j} a_{j}+b)$
那么此时我们面临的问题就是怎么让$\sigma(\sum_{j} w_{j} a_{j}+b)$近似于$f(x)$
在上述情况下,可操作性的无非就是在加权输出上面做文章,所以我们可以设计一个神经网络,其隐藏层有个加权输出:
$$ \sigma^{-1} \circ f(x) $$
其中$\sigma^{-1}$是$\sigma$的反函数
很容易可以得出$\sigma^{-1} \circ f(x)$的结果输入到$\sigma$中输出还是$f(x)$,所以我们控制住了$\sigma(\sum_{j} w_{j} a_{j}+b)$
接下来就是调节参数直到拟合到我们满意的程度(⽬标函数和⽹络实际计算函数的平均偏差来衡量)
多个输入变量 #
上一节已经说明了一个输入和一个输出的普遍性,接下来可以尝试考虑多个输入变量的情况,假设有两个输入:$x,y$,分别对应权重$w_1,w_2$,以及一个神经元上的偏置$b$,看看他们如何影响神经元的输出:
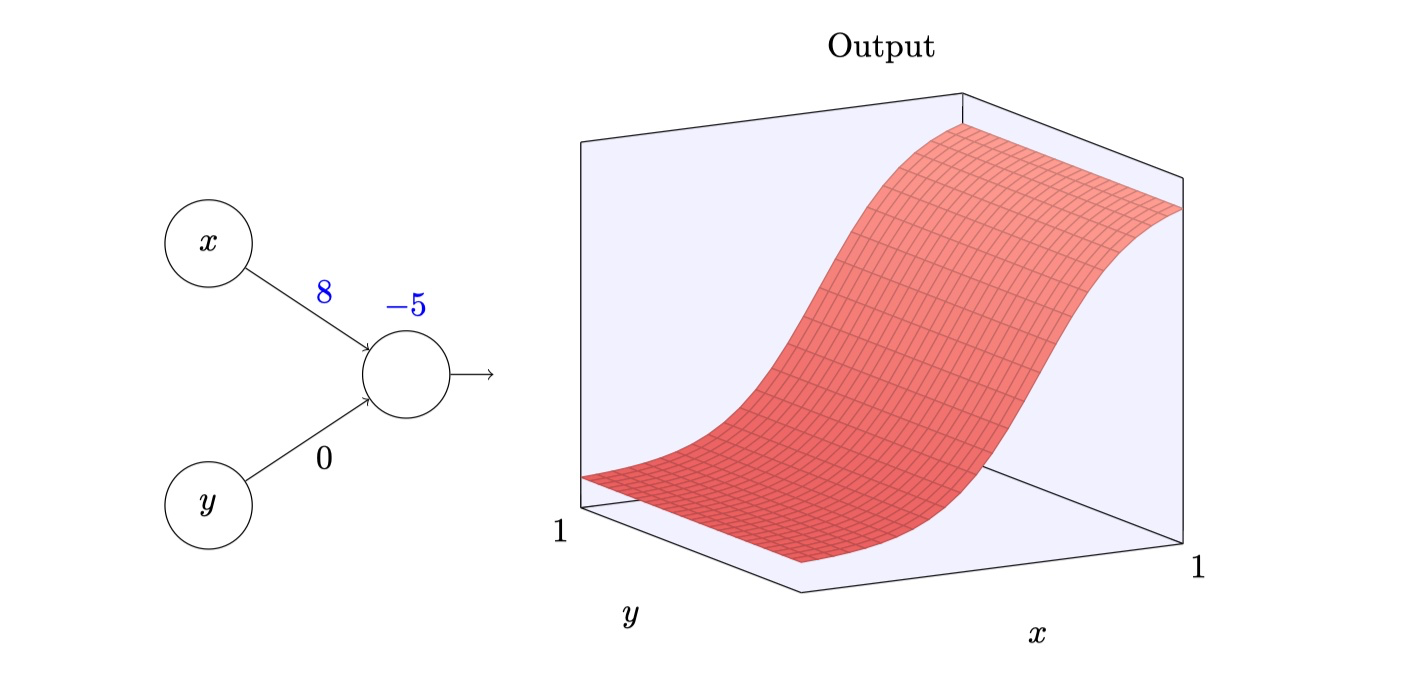
思考:将$w_2$设置为0,再不断调整$w1$,输出会怎样变化?
首先,输出不受输入$y$影响,其次,按照上一节的惯性,图像应该是会变陡峭,会接近到类似阶跃函数,不同的是此时图像是三维的:
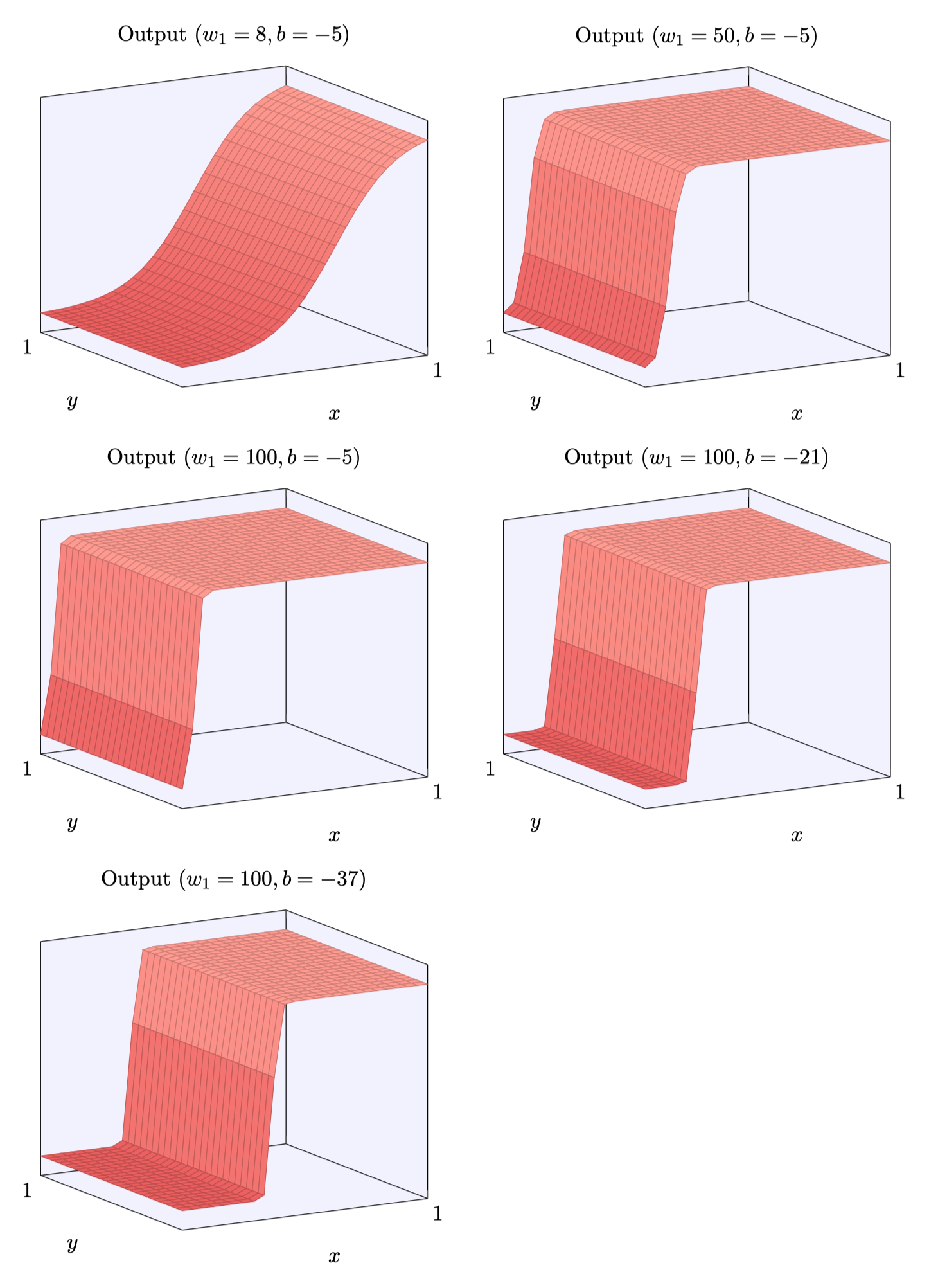
和上面一样,我们可以通过修改偏置的位置来设置移动阶跃点:
$$ s_{x} \equiv-b / w_{1} $$
凸起的期望高度用相应的权重$h$表示,可以通过分别设置x或y输入神经元的权重为0来分别控制y或x方向的凹凸函数
让我们考虑当我们叠加两个凹凸函数时会发⽣什么,⼀个沿$x$⽅向,另⼀个沿$y$⽅向,两者都有⾼度$h$:
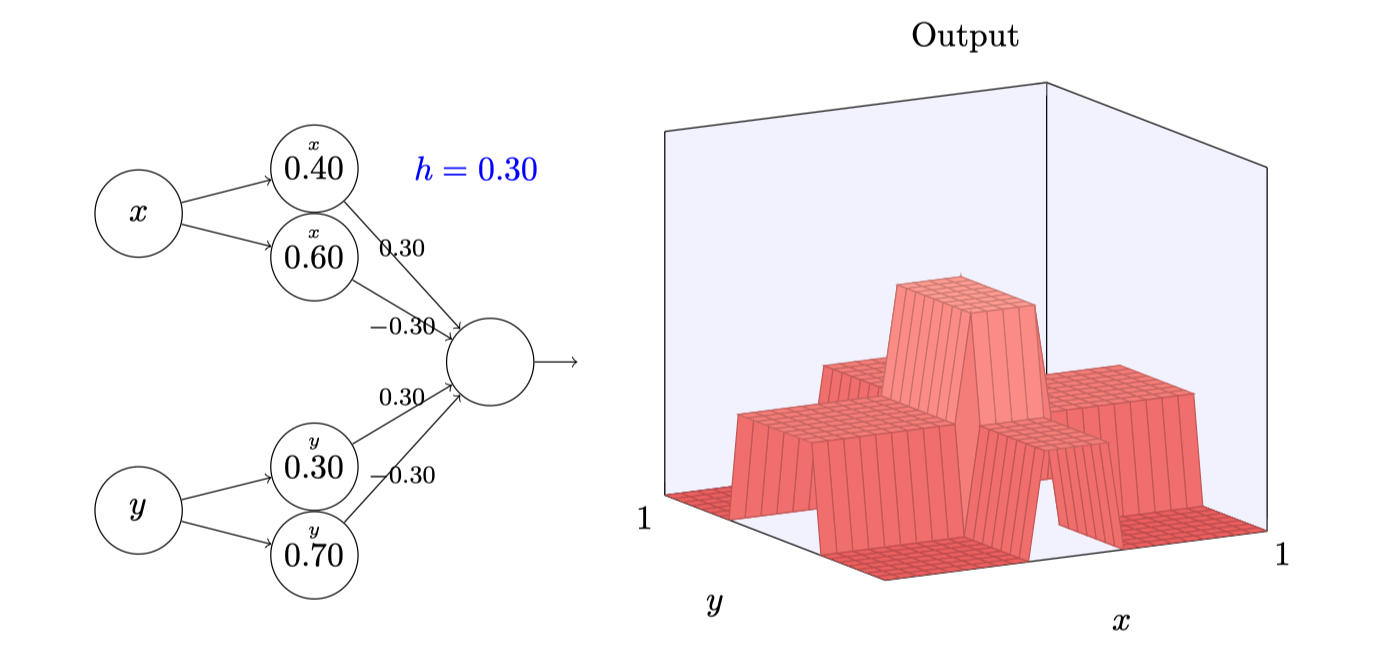
试着改变参数h,正如你能看到,这引起输出权重的变化,以及x和y上凹凸函数的⾼度:
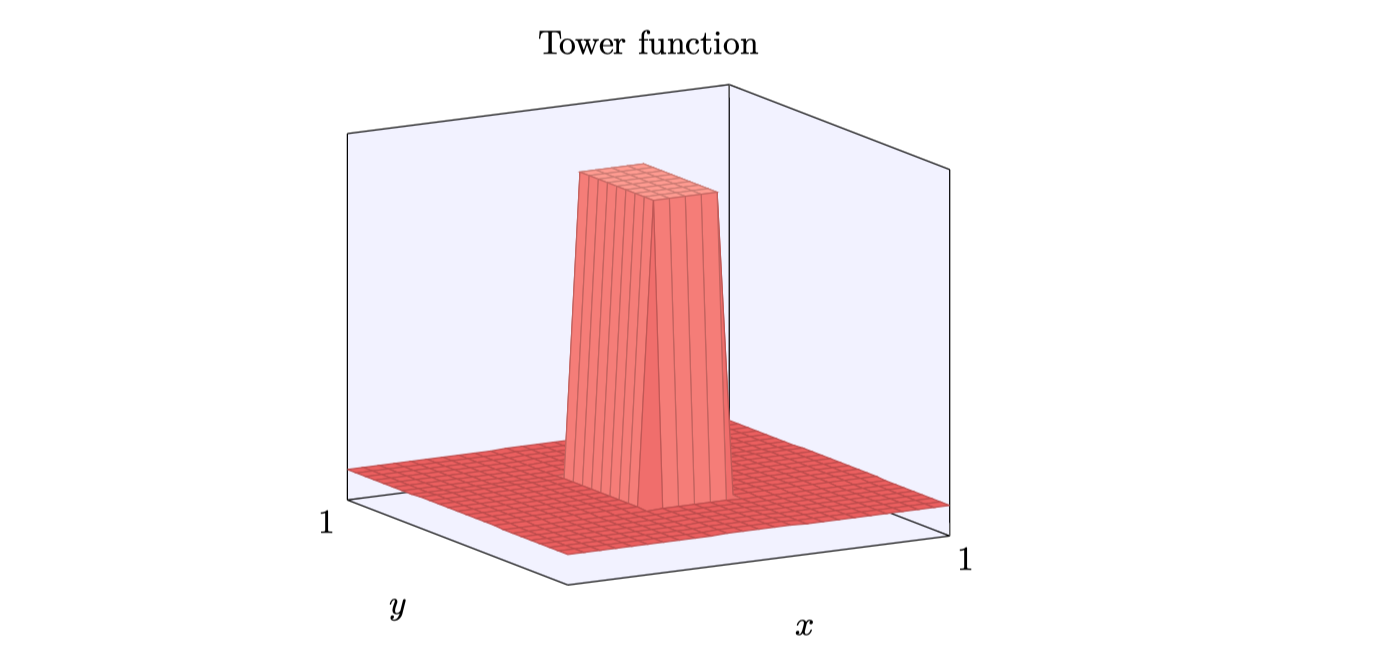
我们构建的有点像是塔形函数,如果我们能构建这样的塔型函数,那么我们能使⽤它们来近似任意的函数,仅仅通过在不同位置累加许多不同⾼度的塔
以此类推,三个变量的四位函数也不在话下,在发散一下思维,$m$维也可以用完全相同的思想来实现。
S型神经元的延伸 #
我们已经证明了由$S$型神经元构成的⽹络可以计算任何函数,若输入为: $x_1, x_2 …x_j$,输出为:
$$ \sigma\left(\sum_{j} w_{j} x_{j}+b\right) $$
其中$\sigma$是$S$型函数,函数图像如下:
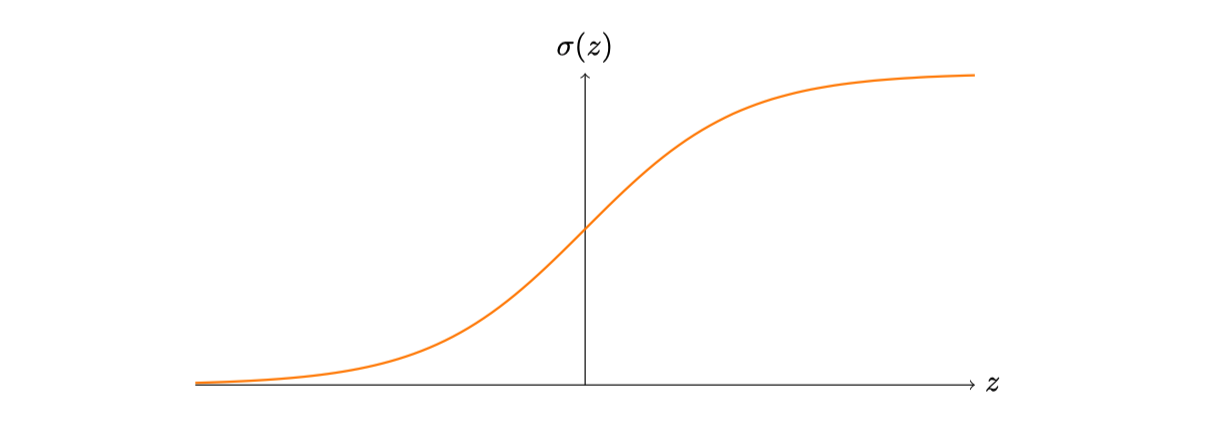
如果我们考虑⼀个不同类型的神经元,它使⽤其它激活函数,⽐如如下的$s(z)$,会怎样?
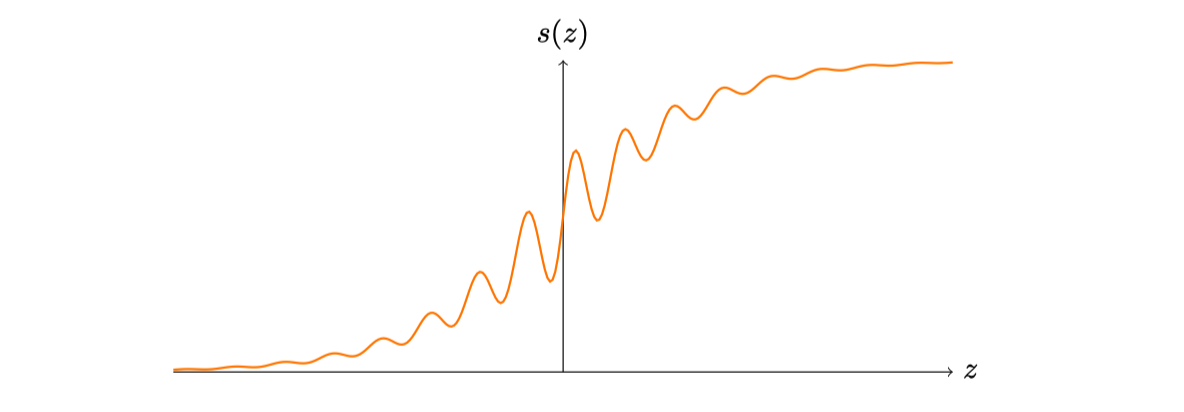
此时神经元的输出为:
$$ s\left(\sum_{j} w_{j} x_{j}+b\right) $$
同样的,我们依然可以利用这个函数来通过对权重和偏置的修改来得到一个阶跃函数的近似:
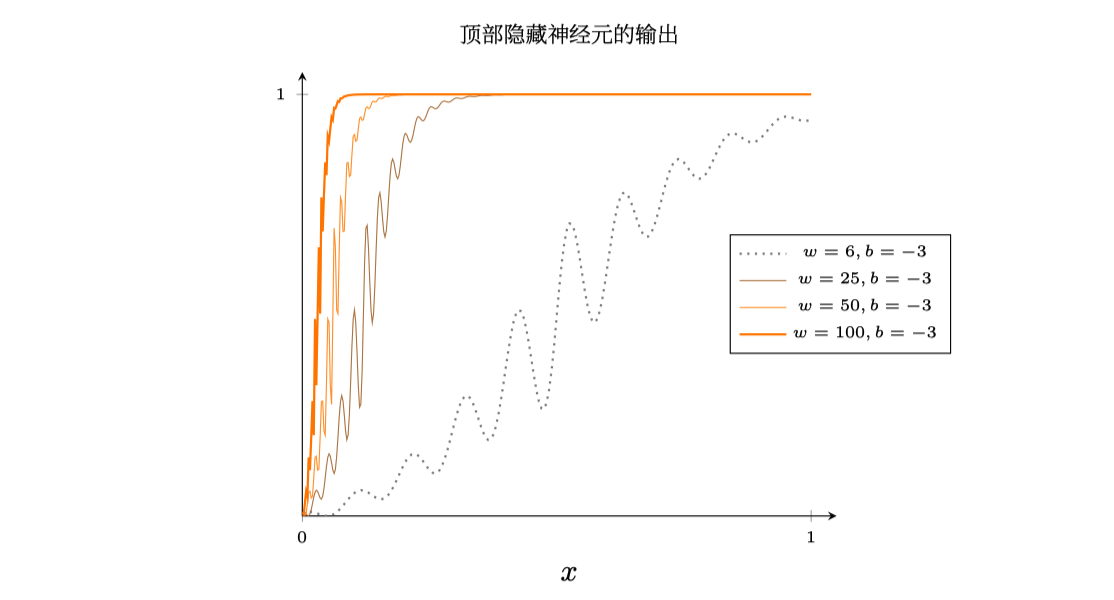
这样我们可以和前面一样来推出任何目标函数,当然,这要求$s(z)$具有以下条件:
- $s(z)$ 在 $z \rightarrow-\infty$ 和 $z \rightarrow \infty$时是定义明确的
- 这两个界限是在我们的阶跃函数上取的两个值,并且这两个界限彼此不同,否则就只能一马平川了哈哈
修补阶跃函数 #
我们用神经元近似阶跃函数的时候,实际上有一个很窄的故障窗口,如下图说明,在这⾥函数会表现得和阶跃函数⾮常不同:
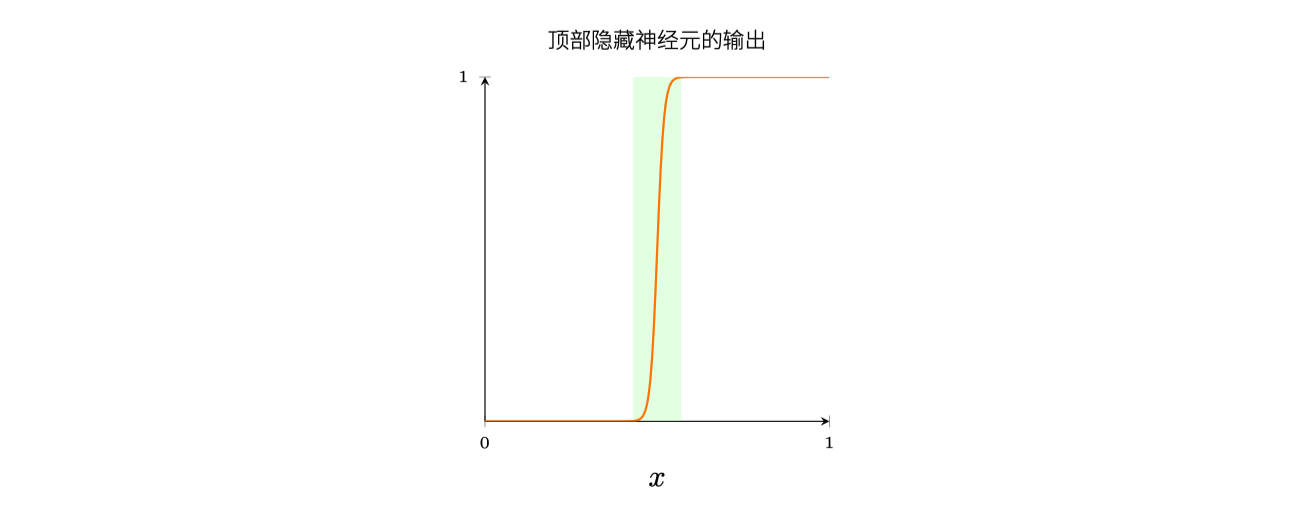
其实理论上来说,只要权重够大,情况可以随着变好,刚刚是从函数本身出发,避免拟合的函数有问题,换个角度,我们可以从拟合的函数出发,我们利用$1/M$的神经元来模拟目标函数的$1/M$,其实也是变相地将目标函数的权重变大,从而达到效果
结论 #
普遍性告诉我们神经⽹络能计算任何函数;而实际经验依据提⽰深度⽹络最能适⽤于学习能够解决许多现实世界问题的函数
本章主要解答了是否使⽤⼀个神经⽹络可以计算任意特定函数的问题,这个自然是的。理论上我们只要两个隐藏层就可以计算任何函数,但深度学习又是什么情况呢?
正如在第⼀章中表明过,深度⽹络有⼀个分级结构,使其尤其适⽤于学习分级的知识,这看上去可⽤于解决现实世界的问题,我个人觉得是单层虽然能拟合各种目标函数,这没错,但是一样的数据,单层网络并不能找到理想中的那个函数,虽然有可能对目前的数据拟合得很好,但是使用深度网络却可以更好地提升泛化能力。
参考 #
搞定收工,有兴趣欢迎关注我的公众号:
