改进神经⽹络的学习⽅法 #

万丈高楼平地起,反向传播是深度学习这栋大厦的基石,所以在这块花多少时间都是值得的
前面一章,我们深入理解了反向传播算法如何工作,本章的主要目的是改进神经网络的学习方法,本章涉及的技术包括:
- 交叉熵代价函数
- 四种称为
规范化的⽅法(L1 和 L2 规范化,弃权和训练数据的⼈为扩展) - 更好的权重初始化⽅法
- 如何选择神经网络的超参数
交叉熵代价函数 #
通过前面的学习,我们知道,神经网络一直在努力地让代价函数变小,现在我们抛出一个问题,代价函数从初始值到我们理想状态的值,这个过程所消耗的时间是怎样的情况呢?
对于人类来说,我们犯比较明显的错误的时候,改正的效果也很明显,神经网络也是这样的么?让我们通过下面的一个小例子来详细看看:
假设有这样一个神经元,我们希望当输入为1的时候,输出为0,让我们通过梯度下降的方式来训练权重和偏置,⾸先将权重和偏置初始化为0.6 和 0.9,前面我们说过,S型神经元的输出计算方式为:
输⼊$x_{1},x_{2},…,x_{j}$,权重为$w_{1},w_{2},…,w_{j}$,和偏置b的S型神经元的输出是:
$$ \frac{1}{1+\exp(-\sum_j w_j x_j-b)} $$
将0.6 和 0.9带入,即可得到输出为:0.82,很显然和目标0相差甚远,那么就只能继续寻找最优解了,随着迭代期的增加,神经元的输出、权重、偏置和代价的变化如下⾯⼀系列图形所⽰:
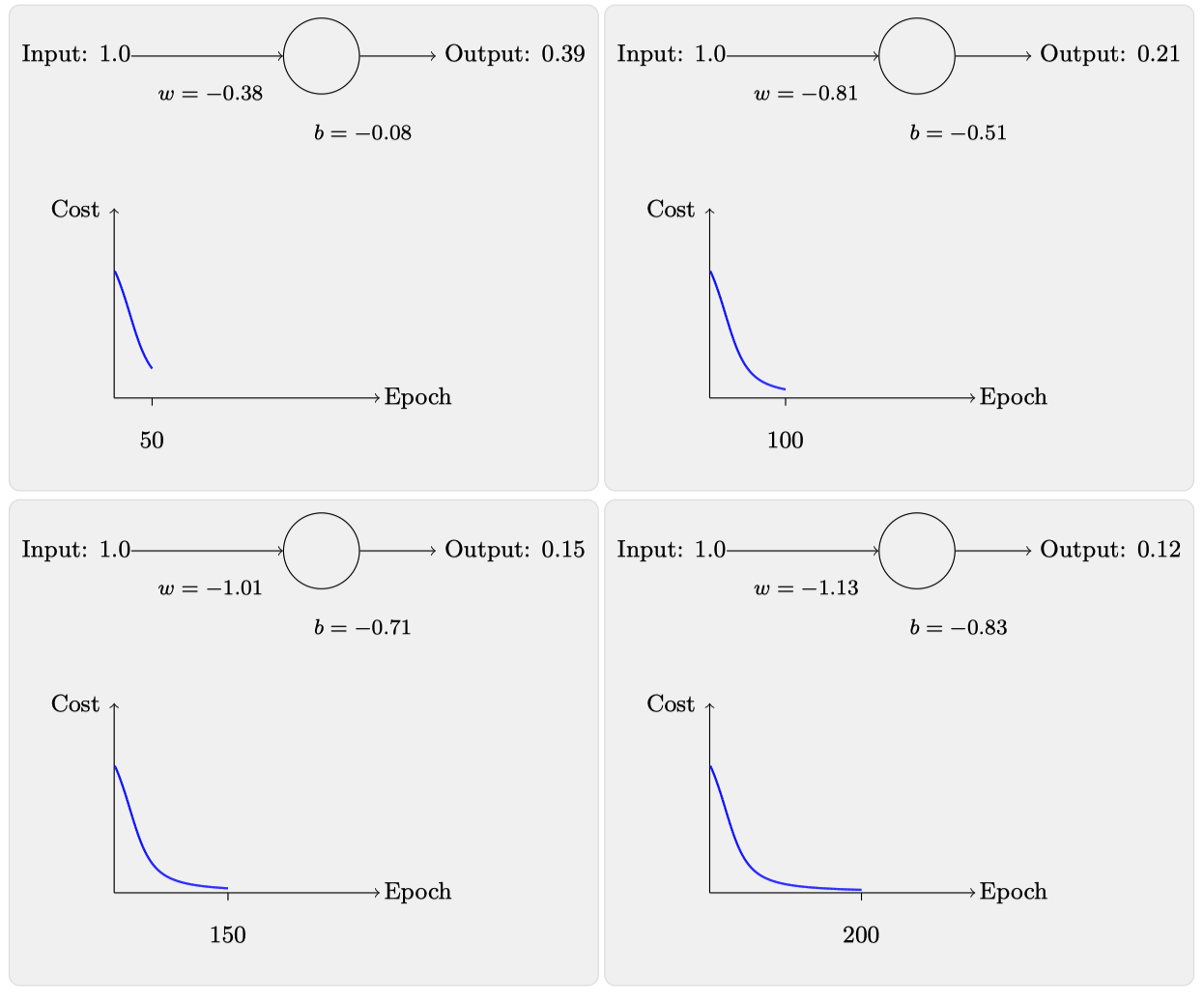
可以看到,200次迭代后,输出已经满足我们的需求了,毕竟只要小于0.5我们都可以归为0,接下来再将初始权重和偏置都设置为2.0,此时初始输出为0.98,这是和⽬标值的差距相当⼤的,现在看看神经元学习的过程:
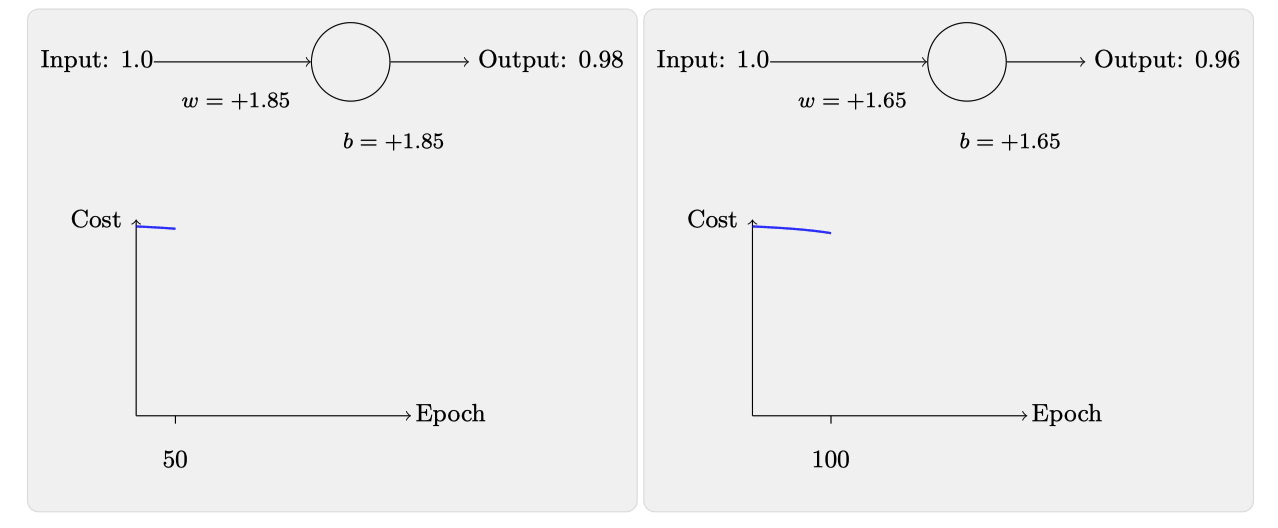
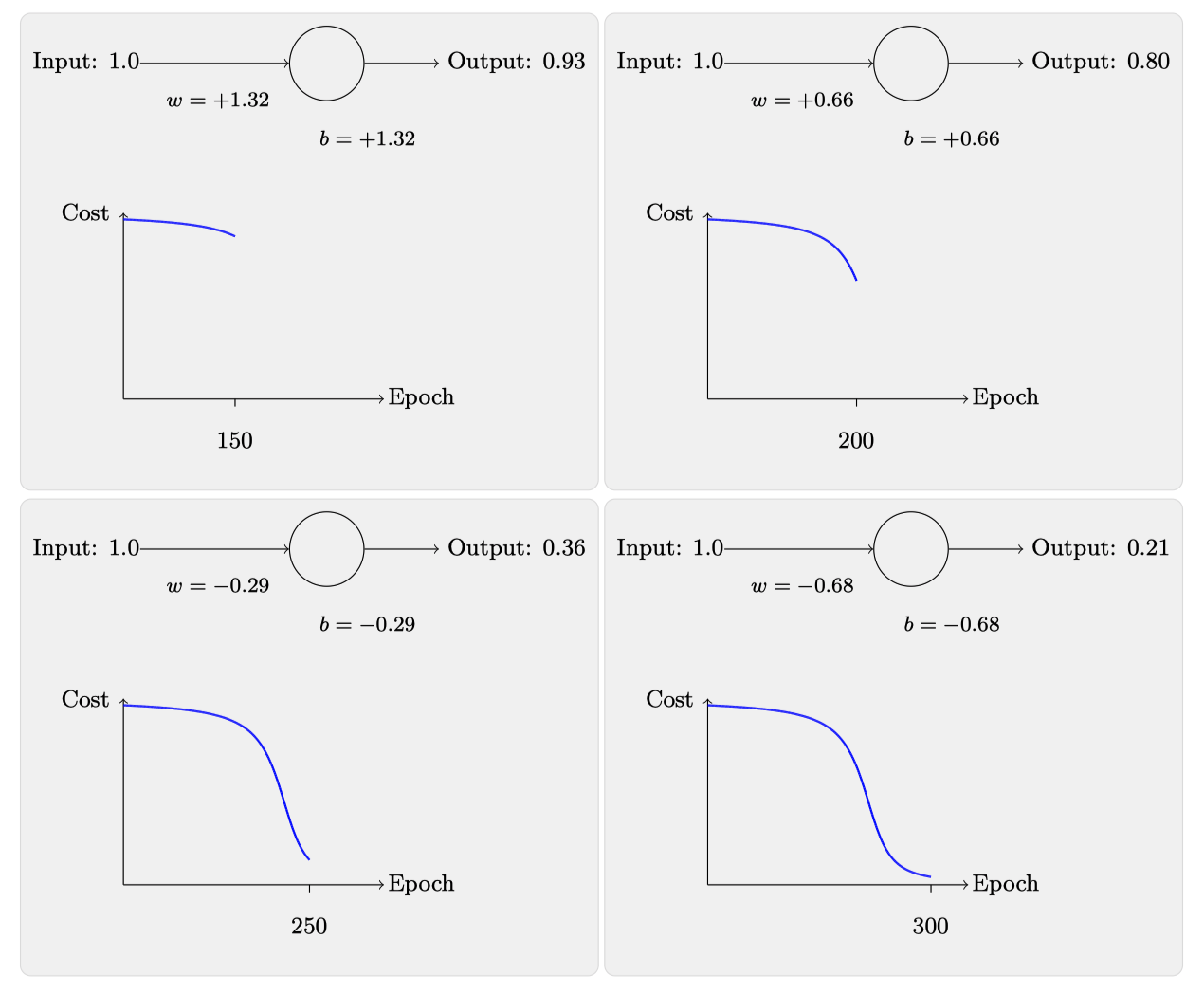
这次可以明显地看到迭代150次左右没有很明显的变化,随后速度就快了起来。
这个例子引出了一个问题,包括在其他一般的神经网络中也会出现,为何会学习缓慢呢?我们在训练中应该怎么避免这个情况?思考一下,问题的原因其实很简单
权重和偏置是根据梯度下降的形式来更新其对应的值,学习缓慢就意味着代价函数的偏导数很小
让我们从数学公式的角度来理解这句话和上面的图,对于目前提供的单个样例的输入和输出:
- $x=1$
- $y=0$
再结合前面第一章讲的代价函数的定义:
$$ C(w,b) \equiv \frac{1}{2n} \sum_x | y(x) - a|^2 $$
- w 表⽰所有的⽹络中权重的集合
- b 是所有的偏置
- n 是训练输⼊数据的个数
- a 是表⽰当输⼊为x时输出的向量,可以理解为output
类比一下,此时的代价函数为:
$$ C=\frac{(y-a)^{2}}{2} $$
接下来就是求权重和偏置的偏导数,推导之前说明一下前面的公式:
- $x=1$
- $y=0$
- $a=\sigma(z)$
- $z=wx+b$
推导过程如下:
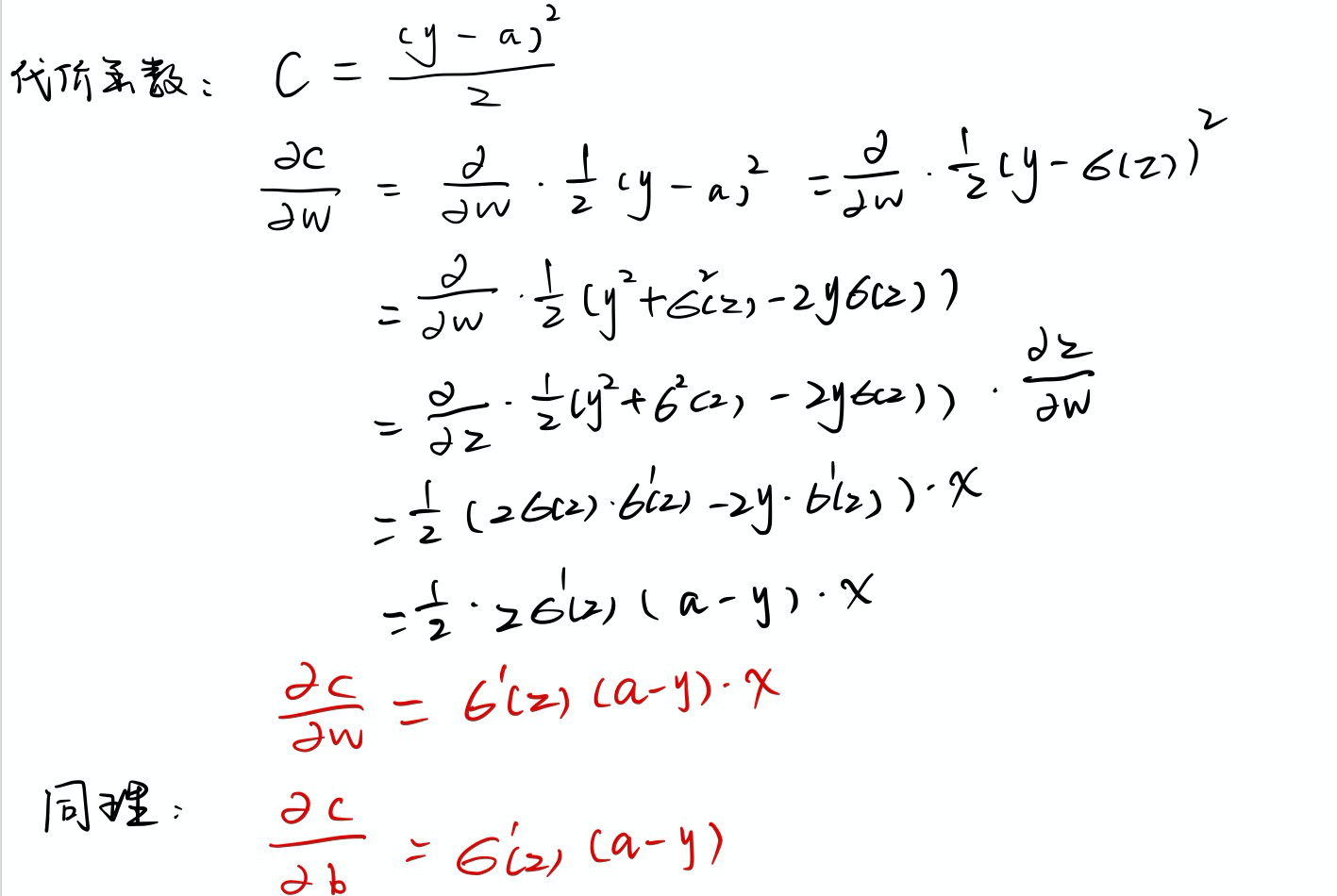
从推导结果可以看到偏导数的值和$\sigma^{\prime}\left(z\right)$成正比,回顾下前面讲的S型神经元中激活函数的图像:
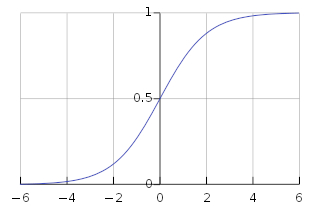
我们可以从这幅图看出,当神经元的输出接近1的时候,曲线变得相当平,所以$\sigma^{\prime}\left(z\right)$就很小,同时也可以得出代价函数C权重和偏置的偏导数也很小,这就是训练速度缓慢的原因
再看上面代价函数值和迭代次数的图,中间部分非常陡峭,前后非常平缓,是不是非常契合$\sigma^{\prime}\left(z\right)$的变化的?类似其他的神经网络,也是这样的原因造成训练缓慢,使用均方误差作为代价函数还有个缺点就是容易陷入局部最优解的沼泽中
引⼊交叉熵代价函数 #
我们已经抛出了神经网络训练缓慢的原因,接下来就是考虑如何解决这个问题
研究表明,我们可以通过使⽤交叉熵代价函数来替换⼆次代价函数
为了理解什么是交叉熵,我们稍微改变⼀下之前的简单例⼦;假设,我们现在要训练⼀个包含若⼲输⼊变量的的神经元,输⼊$x_{1},x_{2},…,x_{j}$,权重为$w_{1},w_{2},…,w_{j}$,和偏置b:
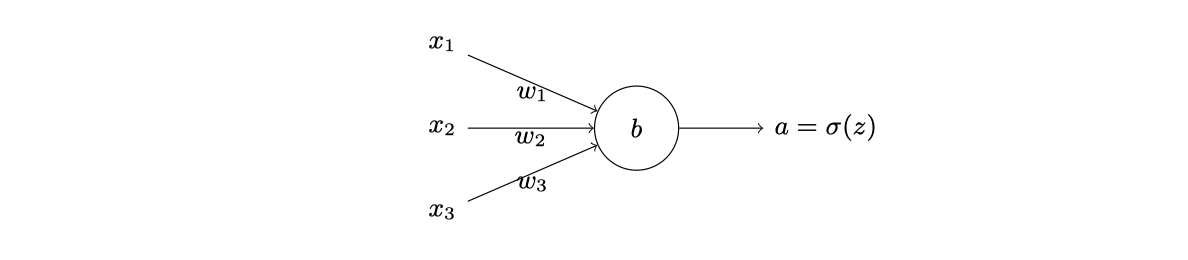
相关说明:
- $a=\sigma(z)$
- $z=\sum_{j} w_{j} x_{j}+b$
我们如下定义这个神经元的交叉熵代价函数:
$$ C=-\frac{1}{n} \sum_{x}[y \ln a+(1-y) \ln (1-a)] $$
其中对数图像如下:
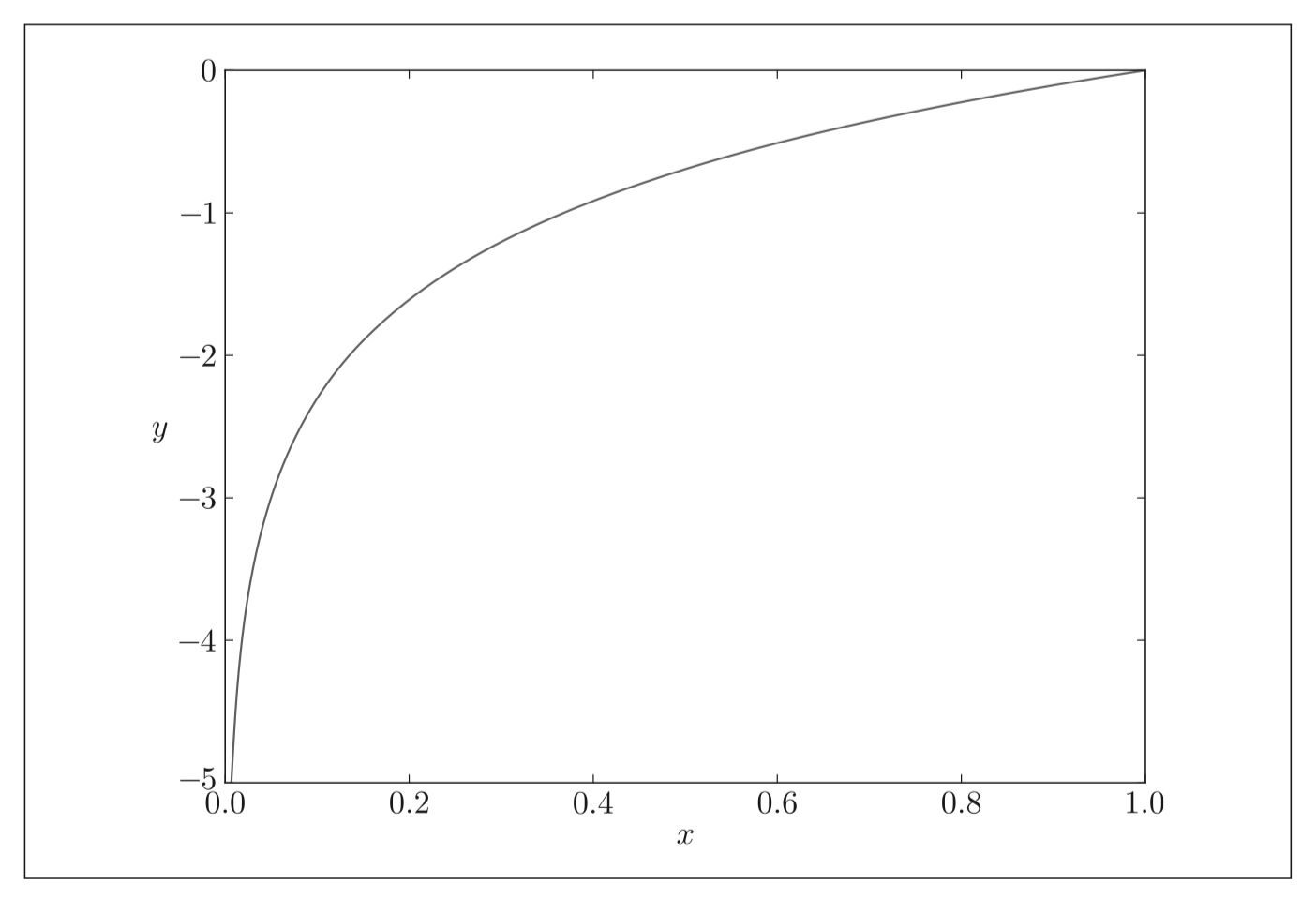
从上面这个公式以及图像可以看出,交叉熵是有资格作为代价函数的:
- 总是非负的
- 实际输出值和目标输出值之间的差距越小,最终的交叉熵的值接越低
交叉熵作为代价函数更好的地方在于避免了学习速度下降的问题,那么到底是怎么解决的呢?很显然,解决问题的关键点在于$\sigma^{\prime}\left(z\right)$,话不多说,先求出代价函数针对$w$和$b$的偏导数再说:

可以看到,$\sigma^{\prime}\left(z\right)$对权重学习的速度直接被消掉了,只和$\sigma(z)-y$成正相关,也就是说输出和实际值的误差越大,学习的速率也就越快
回过头来用交叉熵作为代价函数,看看此时的损失函数值和迭代次数的关系:
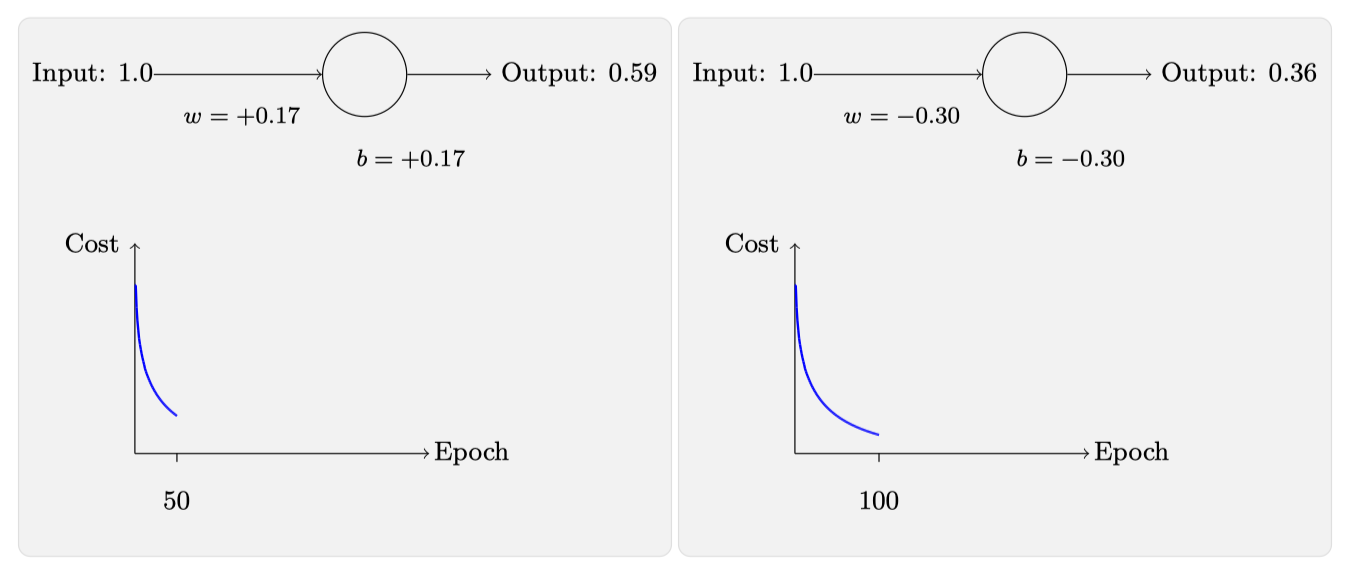
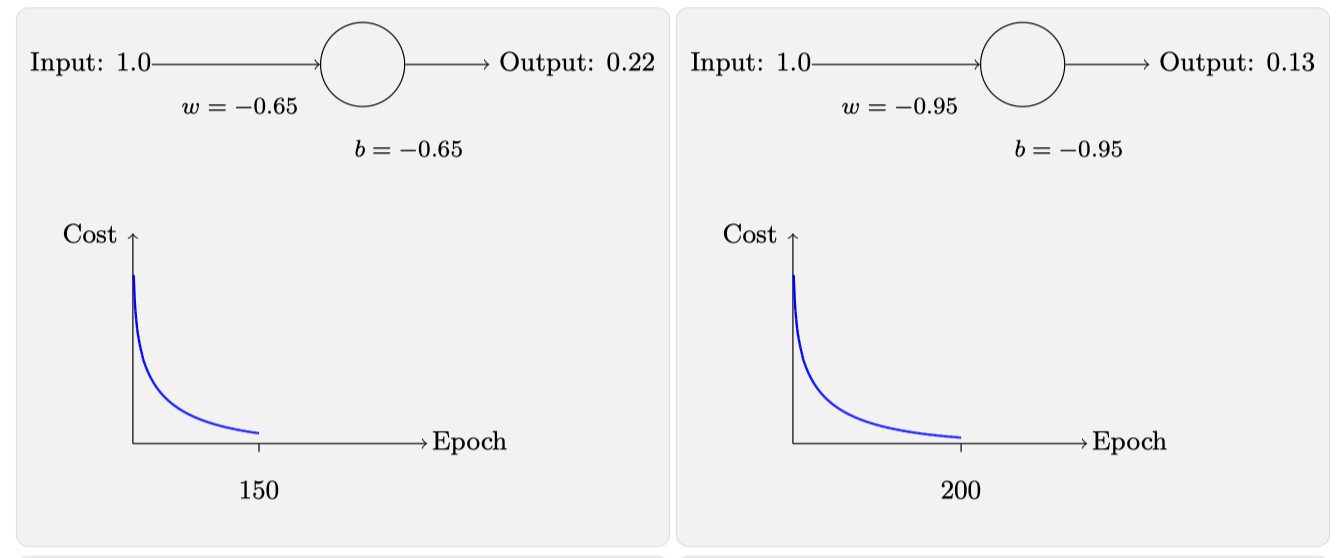
通过对比可以看到此时的变化曲线有以下特点:
- 误差越大,学习速度越快
- 迭代周期明显变小
其推⼴到有很多神经元的多层神经⽹络上的交叉熵公式为:
$$ C=-\frac{1}{n} \sum_{x} \sum_{j}\left[y_{j} \ln a_{j}^{L}+\left(1-y_{j}\right) \ln \left(1-a_{j}^{L}\right)\right] $$
交叉熵的含义?源⾃哪⾥? #
交叉熵可以帮我们完善二次代价函数的缺点,但交叉熵到底是怎么来的呢?
在上一小节,我们有推导二次代价函数对于权重和偏置的偏导数,我们知道造成训练缓慢的原因在于$\sigma^{\prime}\left(z\right)$:
$$ \begin{aligned} \frac{\partial C}{\partial w} &=(a-y) \sigma^{\prime}(z) x=a \sigma^{\prime}(z) \ \frac{\partial C}{\partial b} &=(a-y) \sigma^{\prime}(z)=a \sigma^{\prime}(z) \end{aligned} $$
如果将偏导数里面的$\sigma^{\prime}\left(z\right)$去掉,这样做会产生一个怎样的结果呢?
$$ \begin{aligned} \frac{\partial C}{\partial w_{j}} &=x_{j}(a-y) \ \frac{\partial C}{\partial b} &=(a-y) \end{aligned} $$
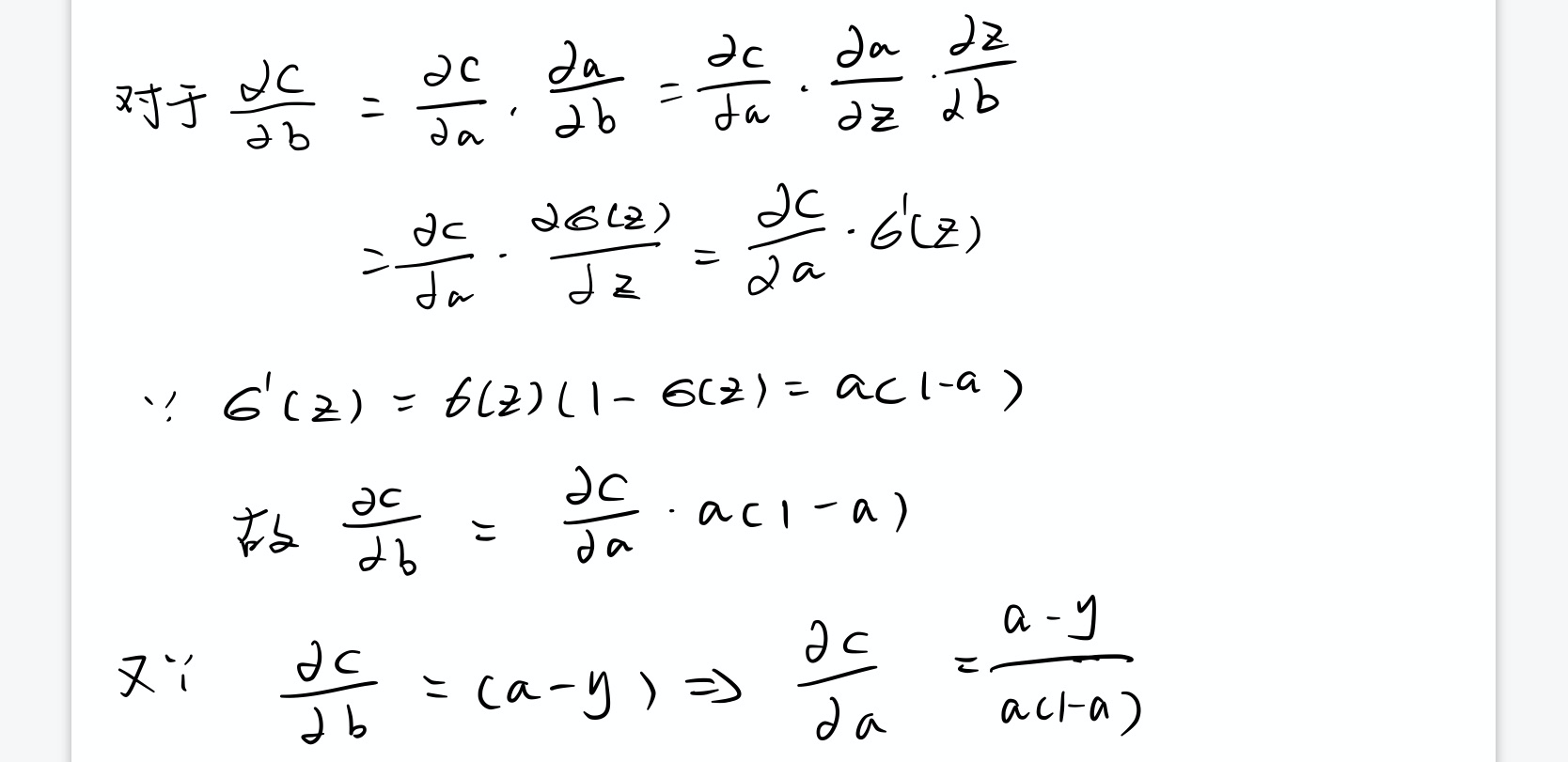
对此⽅程关于a进⾏积分,得到:
$$ C=-[y \ln a+(1-y) \ln (1-a)]+\mathrm{constant} $$
这是⼀个单独的训练样本$x$对代价函数的贡献,为了得到整个的代价函数,我们需要对所有的训练样本进⾏平均, 得到了:
$$ C=-\frac{1}{n} \sum_{x}[y \ln a+(1-y) \ln (1-a)]+\mathrm{constant} $$
过度拟合和规范化 #
如何解决模型在训练过程中出现的过拟合问题
规范化 #
增加训练样本的数量是⼀种减轻过度拟合的⽅法,但是样本本身就是比较稀缺的资源
还有其他的⼀下⽅法能够减轻过度拟合的程度吗?⼀种可⾏的⽅式就是降低⽹络的规模,然⽽,⼤的⽹络拥有⼀种⽐⼩⽹络更强的潜⼒,能使用大的网络更好
我们可以使用规范化的技术来缓解过拟合问题,常见的手段是权重衰减(weight decay)或者L2 规范化,L2规范化的想法是增加⼀个额外的项到代价函数上,这个项叫做规范化项(统计学习方法中引入的结构风险),下⾯是规范化的交叉熵:
$$ C=-\frac{1}{n} \sum_{x j}\left[y_{j} \ln a_{j}^{L}+\left(1-y_{j}\right) \ln \left(1-a_{j}^{L}\right)\right]+\frac{\lambda}{2 n} \sum_{w} w^{2} $$
公式前面一项是交叉熵的表达式,第二项表示的是所有权重平方的和(使用一个因子$\lambda / 2 n$进行量化调整),其中$\lambda>0$称为规范化参数。
直觉地看,规范化的效果是让⽹络倾向于学习⼩⼀点的权重,其他的东西都⼀样的。⼤的权重只有能够给出代价函数第⼀项⾜够的提升时才被允许。换⾔之,规范化可以当做⼀种寻找⼩的权重和最⼩化原始的代价函数之间的折中。
这两部分之前相对的重要性就由λ的值来控制了: λ越⼩,就偏向于最⼩化原始代价函数,反之,倾向于⼩的权重。
为何规范化可以帮助减轻过度拟合 #
我们已经看到了规范化在实践中能够减少过度拟合了,这是令⼈振奋的,不过这背后的原因还不得⽽知!通常的说法是:
⼩的权重在某种程度上,意味着更低的复杂性,也就对数据给出了⼀种更简单却更强⼤解释,因此应该优先选择。
接下来我们利用一个简单的回归任务对上述解释进行研究,如下一个简单的数据集,我们为其建立模型:
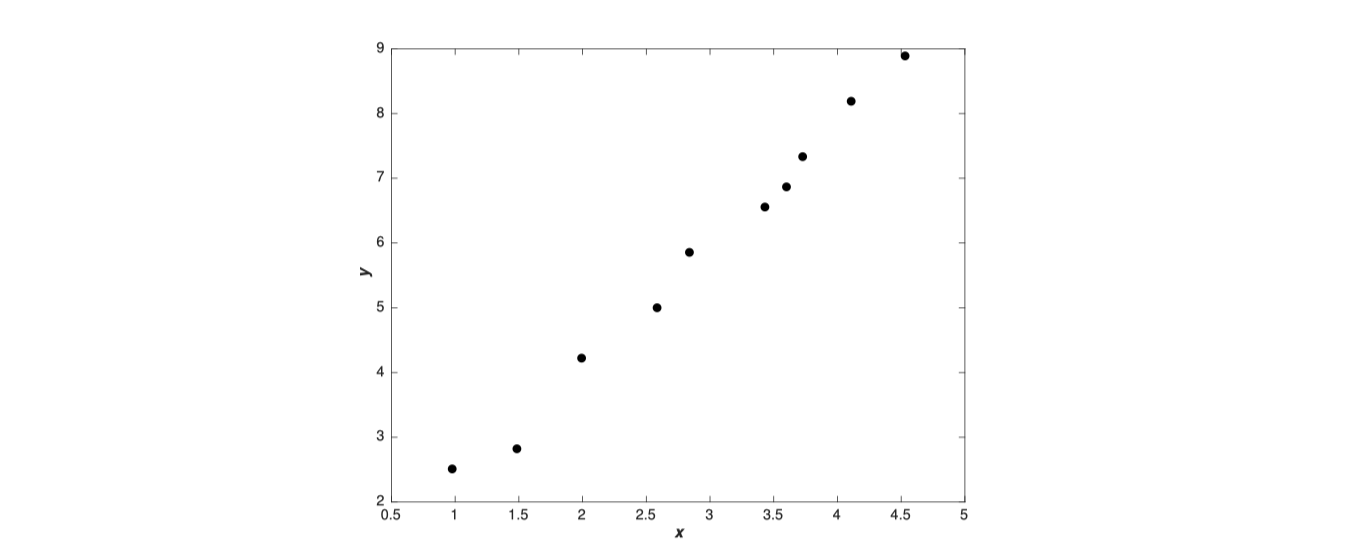
我们先考虑使用多项式来拟合数据:
$$ y=a_{0} x^{9}+a_{1} x^{8}+\ldots+a_{9} $$
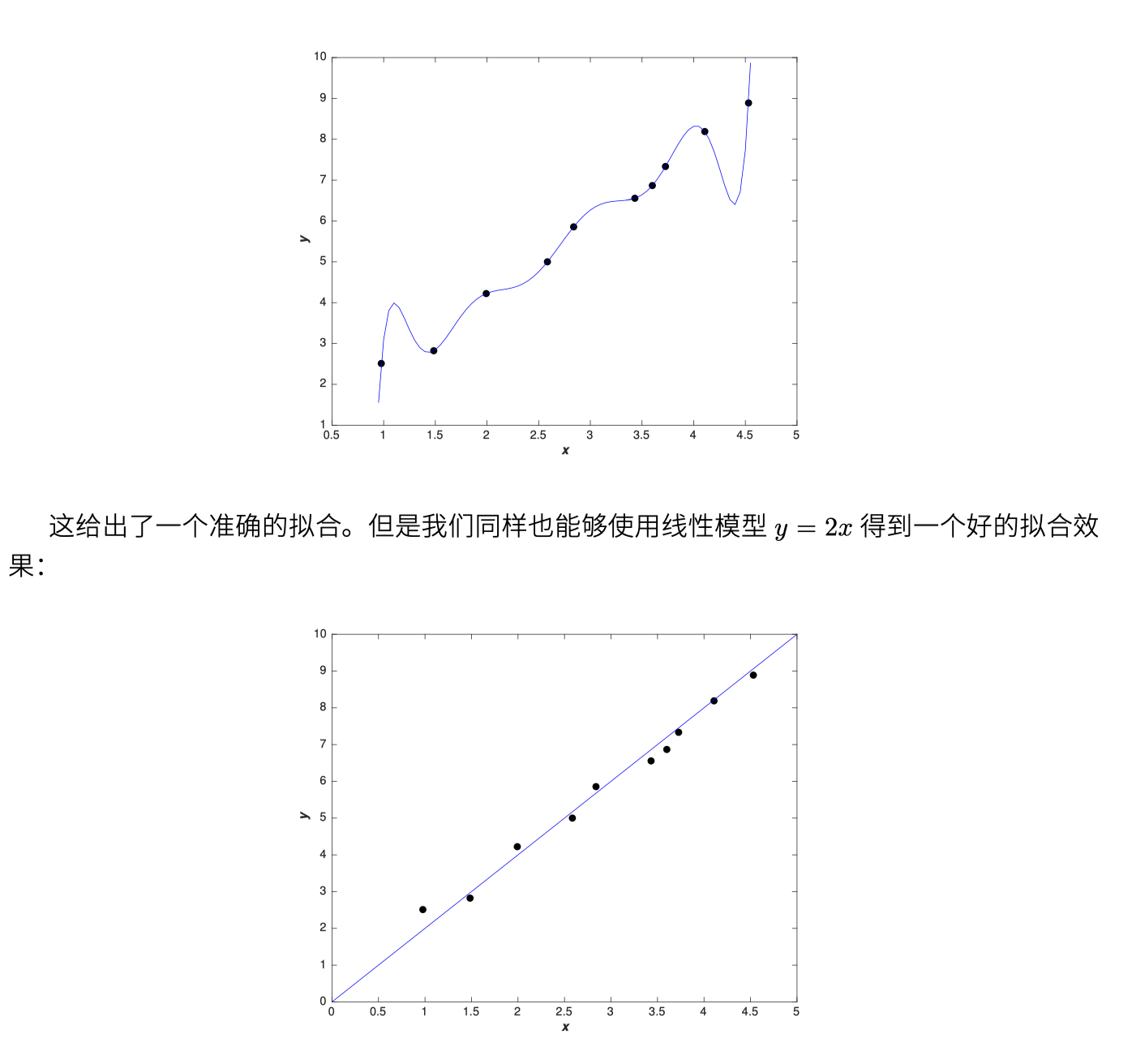
根据奥姆剃刀原则以及我们各自的经验,显然会选择下面的模型。以此类推,丛神经网络的角度,规范化得到的较小的权重应该会更好,实验也证明了这一点。
我们应当时时记住这⼀点,规范化的神经⽹络常常能够⽐⾮规范化的泛化能⼒更强,这只是⼀种实验事实(empirical fact)
规范化的其他技术 #
除了L2外还有很多规范化技术:
- L1规范化
- 弃权(Dropout)
- 人为增加训练样本
L1规范化:这个⽅法是在未规范化的代价函数上加上⼀个权重绝对值的和:
$$ C=C_{0}+\frac{\lambda}{n} \sum_{w}|w| $$
L1规范化倾向于聚集⽹络的权重在 相对少量的⾼重要度连接上,⽽其他权重就会被驱使向0接近
弃权(Dropout):弃权(Dropout)是⼀种相当激进的技术。和L1、L2规范化不同,弃权技术并不依赖对代价函数的修改。
假设我们有⼀个训练数据x和对应的⽬标输出y。通常我们会通过在⽹络中前向传播x,然后进⾏反向传播来确定对梯度的贡献。使⽤弃权技术,这个过程就改了,我们会从随机(临时)地删除⽹络中的⼀半的隐藏神经元开始,同时让输⼊层和输出层的神经元保持不变
⼈为扩展训练数据:数据量大到一定程度可以弥补算法的差距,没啥好说的。
权重初始化 #
创建了神经⽹络后,我们需要进⾏权重和偏置的初始化:之前的⽅式就是根据独⽴⾼斯随机变量来选择权重和偏置,其被归⼀化为均值为0,标准差1
采用均值为0标准差为的⾼斯随机分布初始化这些权重$1 / \sqrt{n_{\mathrm{in}}}$
如何选择神经⽹络的超参数 #
直到现在,我们还没有解释对诸如学习速率η,正则化参数λ等等超参数选择的⽅法,目前只是给出那些效果很好的值而已。实践中,当你使⽤神经⽹络解决问题时,寻找好的超参数其实是比较困难的一件事情。
本节会给出⼀些⽤于设定超参数的启发式想法,⽬的是帮你发展出⼀套⼯作流来确保 很好地设置超参数:
- 宽泛策略:
- 将复杂的问题简单化,比如先减少目标类别,简化网络结构
- 在问题简化后可以方便地进行对超参数进行调节,快速调试是哪个超参数有问题
- 学习速率:可以观察在某些学习速率下,迭代周期和训练代价的折线图变化情况,主要观察训练代价开始下降的学习率,学习速率可以变成可变的,在不同的迭代次数用不同的学习率
- 早停法:这是我个人用得比较多的方法,判断验证集的准确率以及训练代价,比如效果不再提升,就可以考虑停止迭代,输出对应模型
- 正则化参数:开始时不包含正则化(λ = 0.0),确定 η 的值,使⽤确定出来的 η,我们可以使⽤验证数据来选择好的 λ。从尝试 λ = 1.0 开始,然后根据验证集上的性能按照因⼦ 10 增加或减少其值。⼀旦我已经找到⼀个好的量级,你可以改进 λ 的值。这⾥搞定后,你就可以返回再重新优化 η。
- 自动技术:网格搜索
参考 #
搞定收工,有兴趣欢迎关注我的公众号:
