浅谈Python项目开发&管理
本文主要探讨的是个人在Python项目开发&管理这块的一些经验之谈,经过在团队实践后主要内容总结如下:
- 基础环境管理
- 编码标准&规范化
- 远程开发
- 项目脚手架
🐍 环境管理
使用
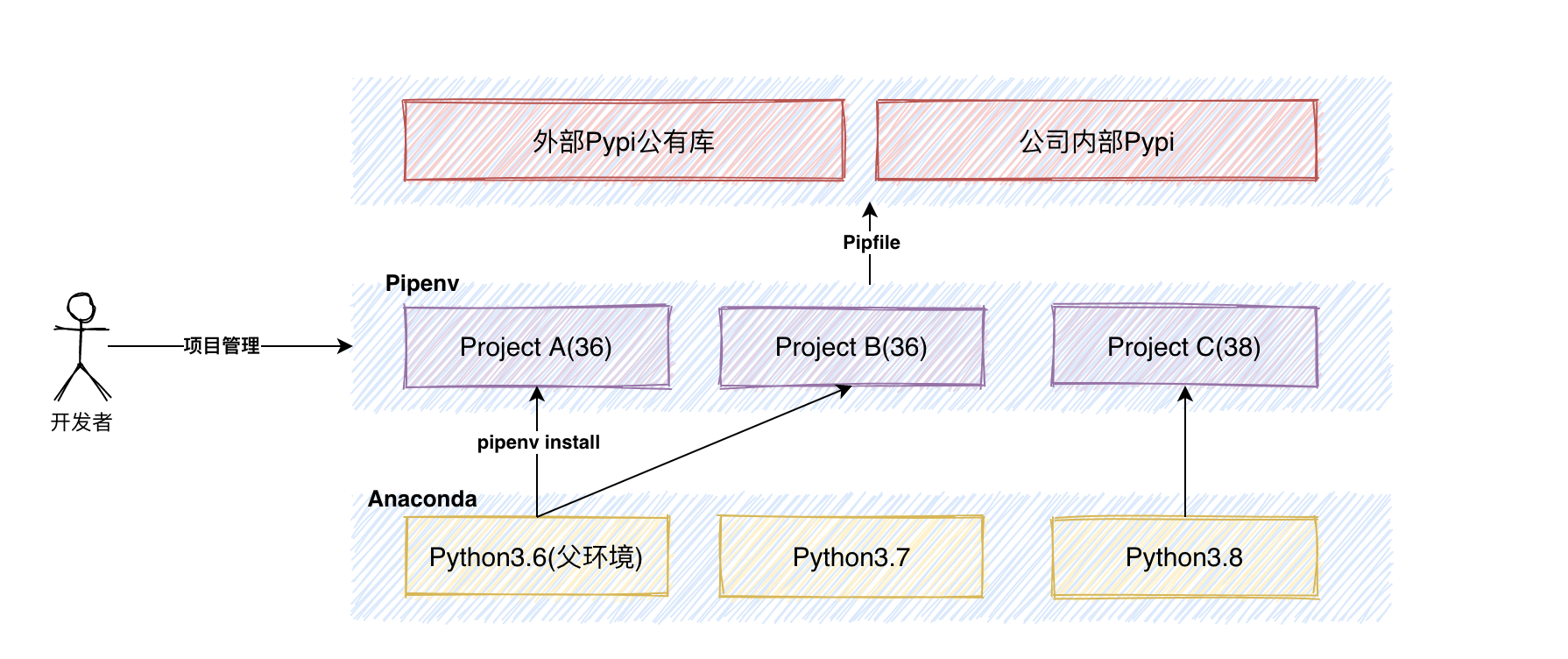
Anaconda和Pipenv共同管理Python项目环境
环境管理这块是个很普遍的问题,其面临的问题如下:
- 如何对不同项目,任意
Python版本的环境进行管控 - 如何对不同项目,内外网
Python依赖库进行管控(有些包是公司内部开发,那么对于项目来说就需要同时管控内外网下的第三方包)
对于上面提到的问题,实际上解决问题的方向都是一致的,那就是引入虚拟环境,使得每个项目都有一个专属环境就可以了。
如果你的公司在生产环境中使用Python有一定的年头,如3~5年,可能有一些老的项目还在用Python3.5甚至Python2.7,那么基本都会面临不同项目不同Python版本的问题。
此时,面对的问题就是第一点提到的不同项目需要的Python环境不同的问题。对于这种情况,可以直接在电脑下载各个版本的Python环境,随后到任意项目下就选用任意版本的Python环境即可,举个例子:
- 项目P_01依赖
Python3.6:分配Python3.6环境 - 项目P_02依赖
Python3.7:分配Python3.7环境
对于各个不同版本Python环境的管理,个人推荐使用Anaconda:
|
|
安装完成后,即可创建不同的Python环境:
|
|
那么对于项目P_01,只需要在项目根目录下进行刚才建立的虚拟环境即可source activate python36,进入相关环境后直接在环境内安装相关依赖包即可。
也就是说,环境python36是专为项目P_01服务的,其他项目只需要再建立一个环境即可。接下来说说为什么引入Pipenv:
- 支持对环境和第三方依赖进行管理
- 很好地管控不同环境下的第三方库,如项目的一部分依赖来自官方,一部分来自公司内部(不能公开)
以我个人举例,构建一个Python项目的基础步骤就是:
|
|
是不是很方便?这一番介绍下来如果你对Anaconda和Pipenv的功能边界还是有疑惑的话,可以看看下方我画的一张图(个人理解,欢迎讨论):
🧬 编码标准
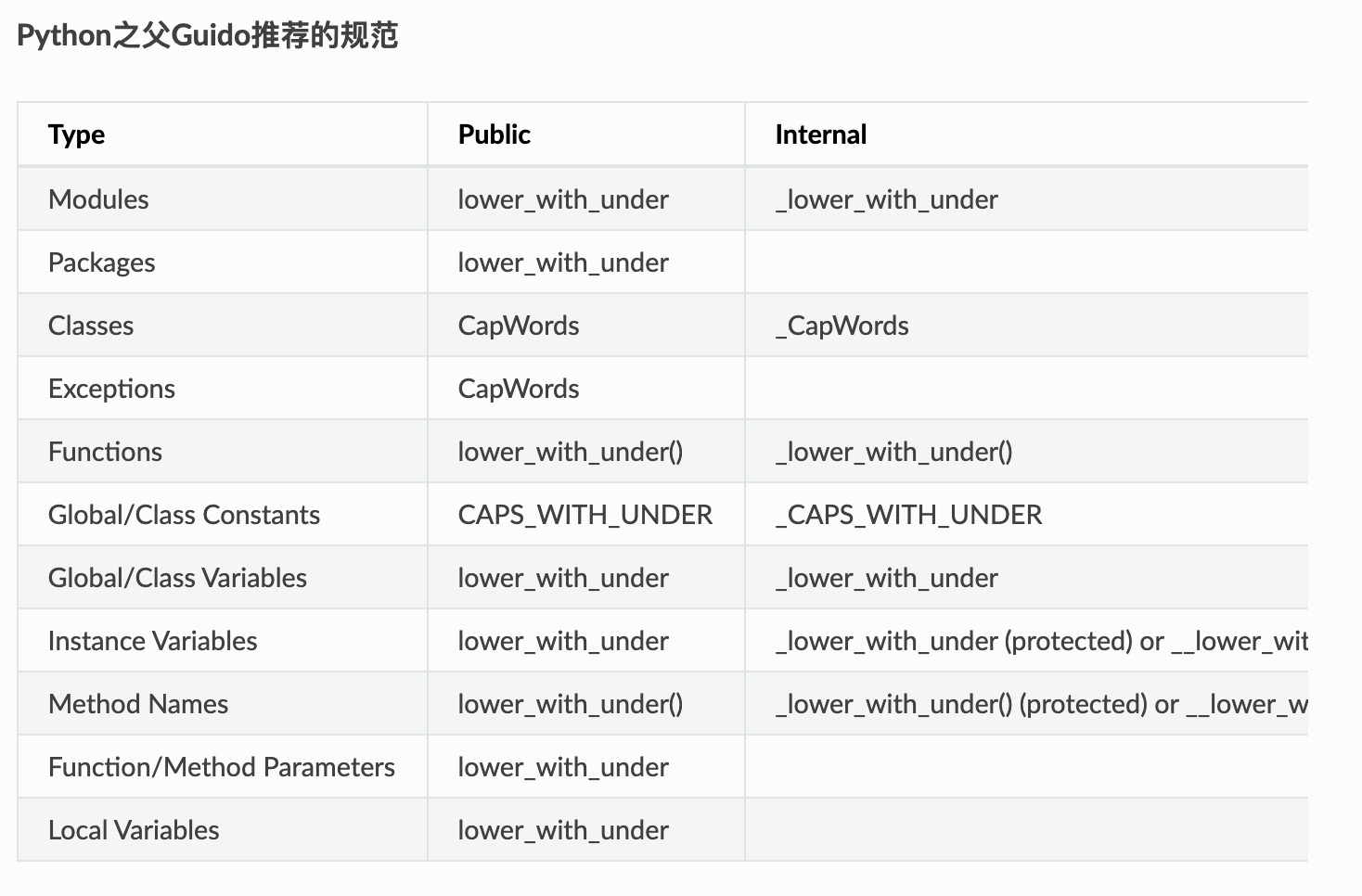
对于编码标准,我推荐跟着社区的PEP8走,之前我就已经翻译过一篇如何用PEP 8编写优雅的Python代码,所以编码标准这块就麻烦诸位移步看下哈。
😎 规范化
所谓标准,如果纯靠人自觉来遵守,实际上就比较理想主义,实际操作下来,我在团队中在规范化这块写了个ci工具,核心就是使用了以下工具来自动标准规范化:
- black:代码格式化
- pylint:代码检查
- isort:导包规划化
- flake8(mccabe):代码复杂度检查
接下来我将以VS Code为例,说一下怎么配置,先进行基础的准备工作:
|
|
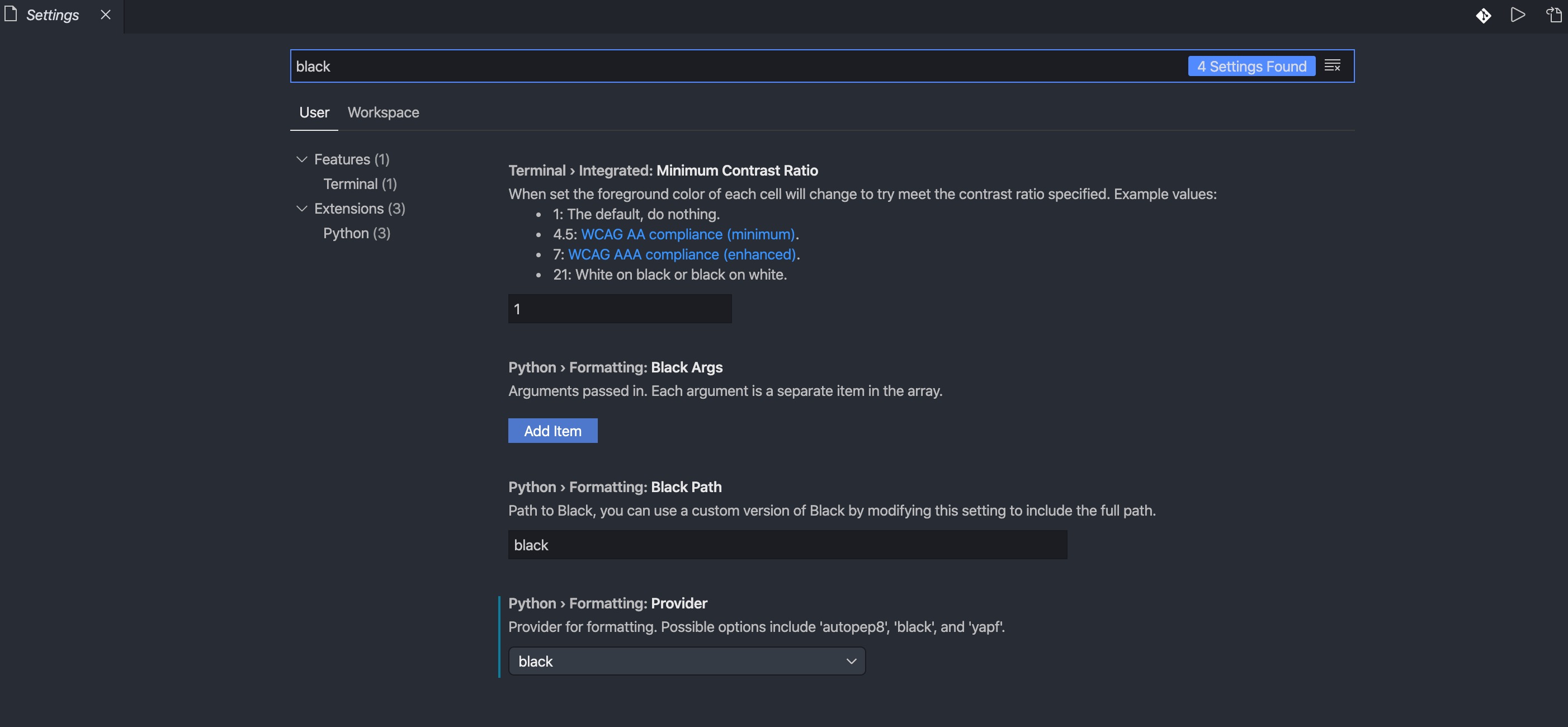
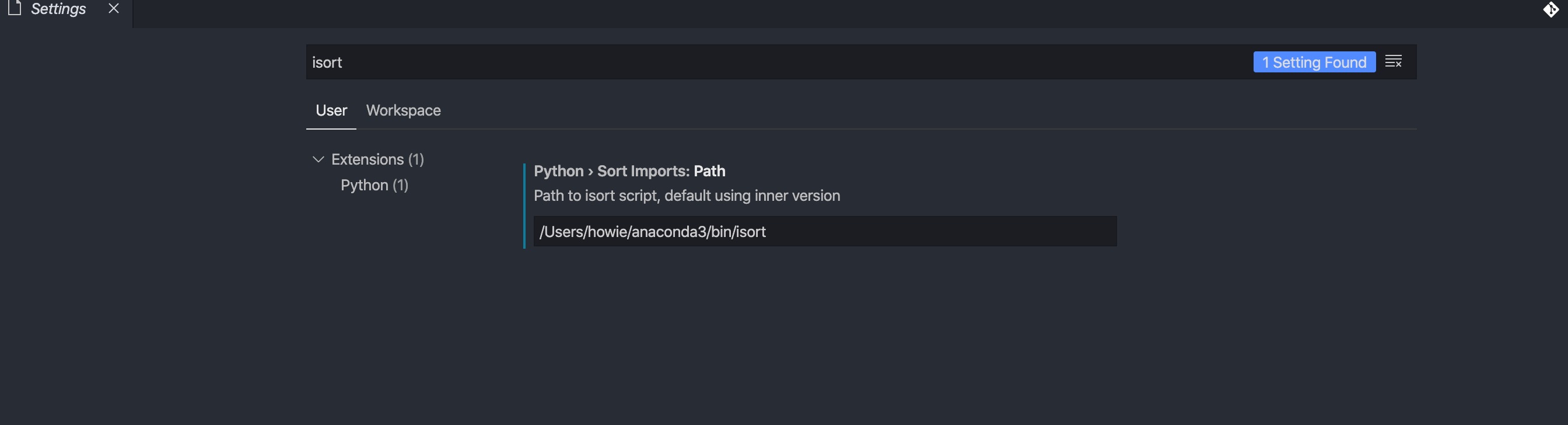
打开VS Code后请先在设置中配置好 python 插件关于 black&isort 的执行路径:
将路径配置好之后,然后在项目根目录新增 setup.cfg :
|
|
注意这里,我们做了flake8关于复杂度的配置,实际上就相当于在根目录执行:
|
|
最后再针对项目进行以下设置:
- 相关配置文件的路径
- 自动保存即自动格式化的
编辑.vscode/settings.json配置文件即可:
|
|
说完了标准化,接下来整起来代码分析工具Pylint ,它分析代码中的错误,查找不符合代码风格标准和有潜在问题的代码。
Pylint 本身的校验还算是比较严格,所以需要添加一些配置限制一些没必要的错误提示,可以在项目根目录下建立文件 .pylintrc :
|
|
然后在项目根目录下执行:
|
|
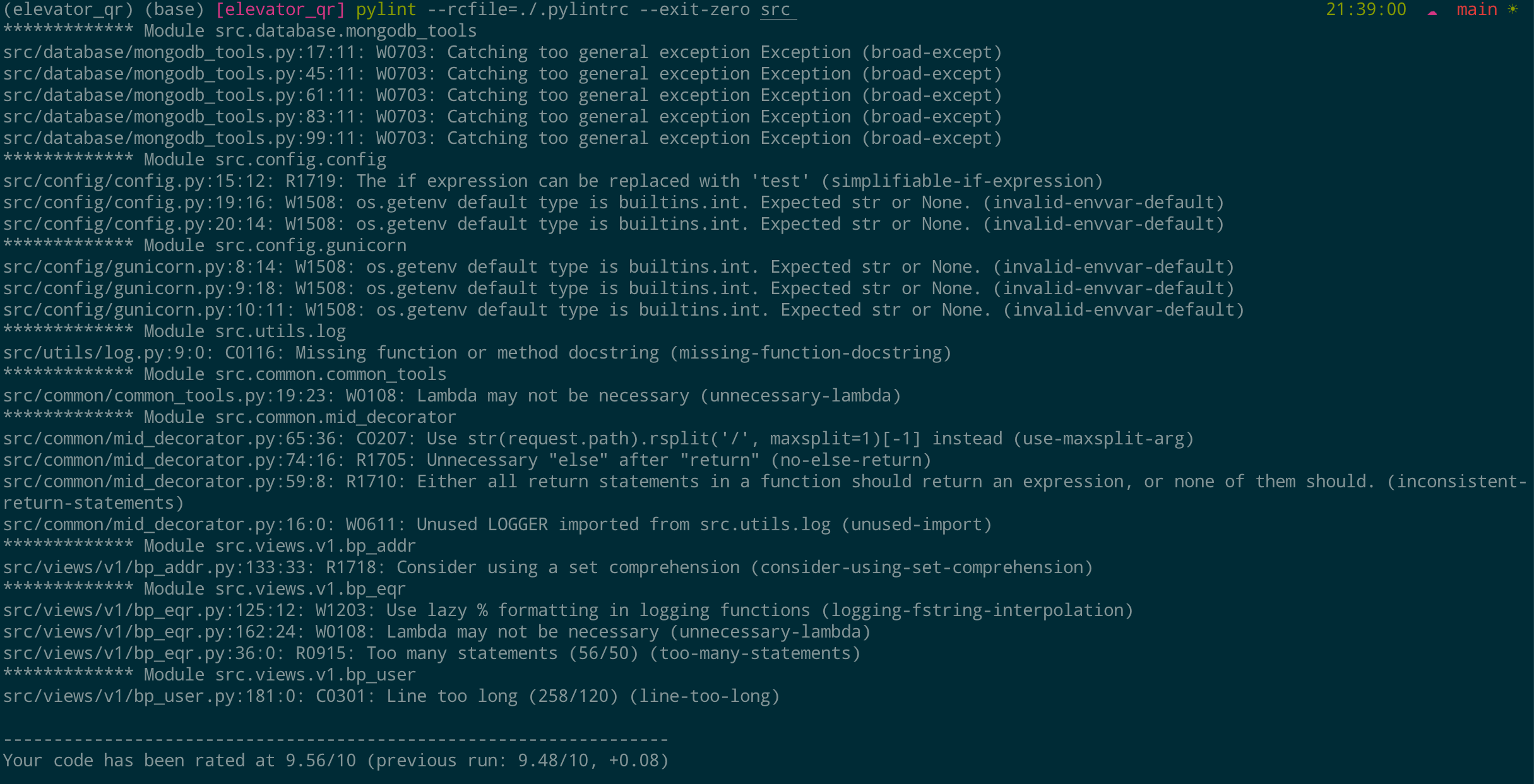
随后就可以看到输出的优化建议以及评分:
👏 远程开发
对于远程开发,我主要调研以下两个方向:
- 在服务器搭建远程开发环境,基于code-server
- 本地编码,利用远程服务器运行,
Pycharm可行,VS Code应该也行
最终我选用了第一个方案,主要其云开发的优势非常吸引人:
- 何时何地能联网就能编码
- 基于Code Server和VS Code一样的手感,香
其实Code Server的安装非常简单,直接执行以下命令(先安装Docker):
|
|
 我基于官方镜像还增加了以下个性化配置,这块大家可以根据自己的喜好来配置:
我基于官方镜像还增加了以下个性化配置,这块大家可以根据自己的喜好来配置:
- 支持oh my zsh
- 使用国内源
- 支持anaconda&pipenv项目管理
- 默认搭建了Python开发环境
- pipenv管理项目
- black&isort&pylint进行标准化
项目脚手架
基于公司业务形成开发标准,再基于开发标准抽象出业务模块,有了通用的业务模块实际上我们就可以构建自己的项目脚手架,我在自己团队中针对业务方向抽象了三个方向的开发代码模板:
- API服务模板:针对接口服务的通用模板,开发者直接在对应文件写逻辑即可,默认配好了服务发现、日志、配置热更、数据库操作、状态码管理等常规模块
- 软实时服务模板:消费数据团队提供的主题,根据输入数据秒级响应结果,比如实时消费登录数据判断是否登录异常,配置了常见模块如消费模块、数据库操作模块、热更配置开发者直接在指定函数写调用业务即可
- 离线服务模板:针对特征提取,基于各大云商,封装各种ETL常用模块,一切目的是为了提升开发效率
有了一些通用的模板,实际上就可以基于模板形成自己的脚手架,举个例子大家可能就比较清楚了,比如某个开发者想要开发一个离线特征提取服务,假设我们脚手架名字叫做oc_demo,那么他只需在终端执行oc_demo,然后跟着脚手架走:
|
|
此时,脚手架就会工作,下拉通用模板,并做一些个性化改动,输出如下:
|
|
此时进入目录,作为开发者只需要在逻辑文件那里新建ETL即可,再也不用:
- 每个成员建立不同风格的模块,维护起来麻烦
- 不用重复性地造或者说复制他人写好的通用模块
- 每个项目风格相同,上手快
🔗 说明
在Python项目管理这块,上面提到核心内容的都是我2018年基于社区的一些默认推荐方式梳理的(远程开发除外),可能是我用着一直觉得没啥问题,所以现在团队用的还是这套,如果大家有什么更好的建议,欢迎交流。
- 原文作者:howie.hu
- 原文链接:https://www.howie6879.com/post/2021/14_about_python_env/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
