k8s学习之路.基础.[02.概念介绍]
俗话说,磨刀不误砍柴工。上一章,我们成功搭建了k8s集群,接下来我们主要花时间了解一下k8s的相关概念,为后续掌握更高级的知识提前做好准备。
本文主要讲解以下四个概念:
PodDeploymentServiceNamespace
引入
让我们使用Deployment运行一个无状态应用来开启此章节吧,比如运行一个nginx Deployment(创建文件:nginx-deployment.yaml):
|
|
配置文件第二行,有个kind字段,表示的是此时yaml配置的类型,即Deployment。什么是Deployment?这里我先不做解释,让我们先实践,看能不能在使用过程中体会出这个类型的概念意义。
在终端执行:
|
|
然后通过以下命令分别查看集群中创建的 Deployment 和 Pod 的状态:
|
|
此时我们已经成功在k8s上部署了一个实例的nginx应用程序。但是,等等!我们好像又看到了一个新的名词Pod,这又是什么?让我们带着疑问继续往下看吧。
Pod
在Kubernetes中,最小的管理元素不是一个个独立的容器,而是pod(目的在于解决容器间紧密协作关系的难题)

Pod是一组并置的容器,代表了Kubernetes中的基本构建模块:
- 一个
Pod包含:- 一个或多个容器(container)
- 容器(container)的一些共享资源:存储、网络等
- 一个
Pod的所有容器都运行在同一个节点
容器可以被管理,但是容器里面的多个进程实际上是不好被管理的,所以容器被设计为每个容器只运行一个进程。
容器的本质实际上就是一个进程,Namespace 做隔离,Cgroups 做限制,rootfs 做文件系统。在一个容器只能运行一个进程的前提下,实际开发过程中一个应用是由多个容器紧密协作才可以成功地运行起来。因此,我们需要另一种更高级的结构来将容器绑定在一起,并将它们作为一个单元进行管理,这就是Pod出现的目的。
如何定义并创建一个Pod
创建文件nginx-pod.yaml:
|
|
相关字段解释如下:
- kind: 该配置的类型,这里是 Pod
- metadata:元数据
- name:Pod的名称
- labels:标签
- spec:期望Pod实现的功能
- containers:容器相关配置
- name:container名称
- image:镜像
- ports:容器端口
- containerPort:应用监听的端口
- containers:容器相关配置
运行:
|
|
这里简单介绍了用声明式API怎么创建Pod,但从技术角度看,Pod又是怎样被创建的呢?实际上Pod只是一个逻辑概念,Pod里的所有容器,共享的是同一个Network Namespace,并且可以声明共享同一个Volume。
Pod除了启动你定义的容器,还会启动一个Infra容器,这个容器使用的就是k8s.gcr.io/pause镜像,它的作用就是整一个Network Namespace方便用户容器加入,这就意味着Pod有以下特性:
- 内部直接使用
127.0.0.1通信,网络设备一致(Infra容器决定) - 只有一个IP地址
Pod的生命周期只跟Infra容器一致,而与用户容器无关
标签
现在我们的集群里面只运行了一个Pod,但在实际环境中,我们运行数十上百个Pod也是一件很正常的事情,这样就引出了Pod管理上的问题,我们可以通过标签来组织Pod和所有其他Kubernetes对象。
前面nginx-pod.yaml里面就声明了labels字段,标签为name,相关操作记录如下:
|
|
命名空间
利用标签,我们可以将Pod和其他对象组织成一个组,这是最小粒度的分类,当我们需要将对象分割成完全独立且不重叠的组时,比如我想单独基于k8s搭建一套Flink集群,我不用想让我的Flink和前面搭建的Nginx放在一起,这个时候,命名空间(namespace)的作用就体现出来了。
|
|
让我们创建一个命名空间vim cus-ns.yaml,输入:
|
|
让我们在终端实践一番:
|
|
这里我们可以暂时先做一个总结,如前面所说,Pod可以表示k8s中的基本部署单元。经过前面的讲解,你应该知道以下一些知识点:
- 手动增删改查
Pod - 让其服务化(
Service)
但是在实际使用中,我们并不会直接人工干预来管理Pod,为什么呢?当Pod健康出问题或者需要进行更新等操作时,人是没有精力来做这种维护管理工作的,但我们擅长创造工具来自动化这些繁琐的事情,所以我们可以使用后面介绍的Deployment。
外部访问
此时我们已经启动了一个nginx,我们有哪些方法可以对Pod进行连接测试呢?
可以使用如下命令:
|
|
显然,成功访问,但是这个有个问题就是此端口不会长期开放,一旦一定时间内没有访问,就会自动断掉,我们需要其他的方式来进行访问,比如后面会提到的Service,这里就简单运行个命令,大家感受一下:
|
|
Service
Service 服务的主要作用就是替代 Pod 对外暴露一个不变的访问地址
在本文第二节Pod部分的外部访问小节,就已经提到并演示了Service,它很方便地将我们的服务端口成功开放给外部访问。
介绍
我们的Pod是有生命周期的,它们可以被创建、销毁,但是一旦被销毁,这个对象的相关痕迹就没有了,哪怕我们用ReplicaSet让他又复生了,但是新Pod 的IP我们是没法管控的。
很显然,如果我们的后端服务的接口地址总是在变,我们的前端人员心中定然大骂,怎么办?这就轮到Service出场了。
定义 Service
前面我们创建了一个名为nginx-http的Services,用的是命令行;接下来我们介绍一下配置文件的形式,在nginx-deployment.yaml后面增加以下配置:
|
|
相信上述配置,大部分的字段看起来都没什么问题了吧,先说一下端口这块的含义:
- nodePort:通过任意节点的
30068端口来访问Service - port:集群内的其他容器组可通过
8068端口访问Service - targetPort:
Pod内容器的开发端口
这里我想强调的是type字段,说明如下:
- ClusterIP:默认类型,服务只能够在集群内部可以访问
- NodePort:通过每个 Node 上的 IP 和静态端口(
NodePort)暴露服务 - LoadBalancer:使用云提供商的负载均衡器,可以向外部暴露服务。
关于LoadBalancer,基本上是云商会提供此类型,如果是我们自行搭建的,就没有此类型可选,但是很多开源项目默认是启用这种类型,我们可以自行打一个补丁来解决这个问题:
|
|
执行生效命令:
|
|
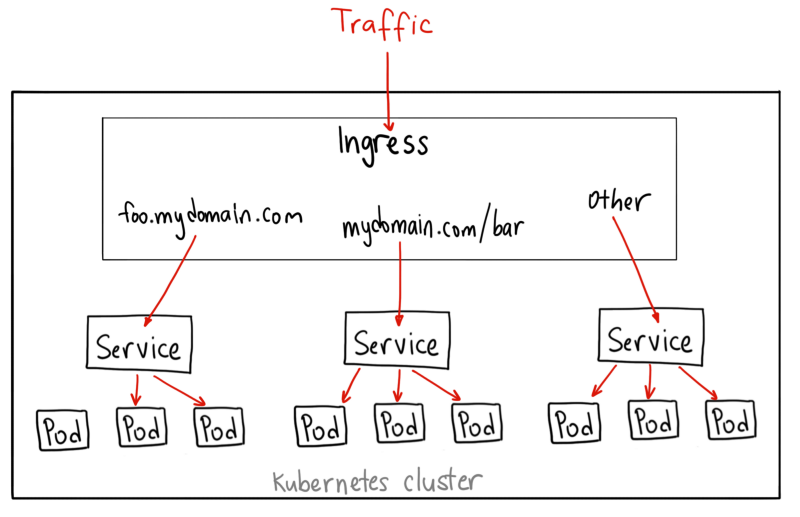
除了前面提的两种方法(NodePort、LoadBalancer),还有另外一种方法——Ingress资源。我们为什么需要引入Ingress,最主要的原因是LoadBalancer需要公有的IP地址,自行搭建的就不要考虑了。
而Ingress非常强大,它位于多个服务之前,充当集群中的智能路由器或入口点:
Deployment
窥一斑而知全豹,好好了解完Pod之后,再继续了解k8s的概念也就水到渠成了。我们一般不会直接创建Pod,毕竟通过创建Deployment资源可以很方便的创建管理Pod(水平扩展、伸缩),并支持声明式地更新应用程序。
介绍
本章第一小节引入部分就是以Deployment举例,当时启动配置文件我们看到了一个Deployment资源和一个Pod,查看命令如下:
|
|
这里我们再增加一条命令:
|
|
嗯嗯~,让我们捋一捋,当我们创建一个Deployment对象时,k8s不会只创建一个Deployment资源,还会创建另外的ReplicaSet 以及1个Pod 对象。所以问题来了, ReplicaSet又是个是什么东西?
ReplicaSet
如果你更新了Deployment的Pod模板,那么Deployment就需要通过滚动更新(rolling update)的方式进行更新。
而滚动更新,离不开ReplicaSet,说到ReplicaSet就得说到ReplicationController(弃用)。
ReplicationController是一种k8s资源,其会持续监控正在运行的pod列表,从而保证Pod的稳定(在现有Pod丢失时启动一个新Pod),也能轻松实现Pod的水平伸缩
ReplicaSet的行为与ReplicationController完全相同,但Pod选择器的表达能力更强(允许匹配缺少某个标签的Pod,或包含特定标签名的Pod)。所以我们可以将Deployment当成一种更高阶的资源,用于部署应用程序,并以声明的方式管理应用,而不是通过ReplicaSet进行部署,上述命令的创建关系如下图:

如上图,Deployment的控制器,实际上控制的是ReplicaSet的数目,以及每个ReplicaSet的属性。我们可以说Deployment是一个两层控制器:
Deployment–>ReplicaSet–>Pod
这种形式下滚动更新是极好的,但这里有个前提条件那就是Pod是无状态的,如果运行的容器必须依赖此时的相关运行数据,那么回滚后这些存在于容器的数据或者一些相关运行状态值就不存在了,对于这种情况,该怎么办?此时需要的就是StatefulSet(部署有状态的多副本应用)。
StatefulSet
如果通过ReplicaSet创建多个Pod副本(其中描述了关联到特定持久卷声明的数据卷),那么这些副本都将共享这个持久卷声明的数据卷。
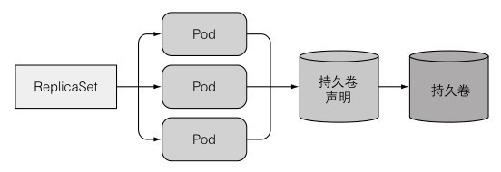
那如何运行一个pod的多个副本,让每个pod都有独立的存储卷呢?对于这个问题,之前学习的相关知识都不能提供比较好的解决方案。k8s提供了Statefulset资源来运行这类Pod,它是专门定制的一类应用,这类应用中每一个实例都是不可替代的个体,都拥有稳定的名字和状态。
对于有状态的应用(实例之间有不对等的关系或者依赖外部数据),主要需要对以下两种类型的状态进行复刻:
- 存储状态:应用的多个实例分别绑定了不同的存储数据,也就是让每个Pod都有自己独立的存储卷
- 拓扑状态:应用的多个实例之间不是完全对等的关系,各个Pod需要按照一定的顺序启动
参考
本章的基本概念就介绍到这里了,谢谢!本部分内容有参考如下文章:
- 学习Kubernetes基础知识
- 详解 Kubernetes Deployment 的实现原理
- Kubernetes 中文指南:Deployment
- Kubernetes 中文指南:Service
- 深入剖析Kubernetes:容器编排部分
- Kubernetes in Action中文版:第3、4、5、9章
- 原文作者:howie.hu
- 原文链接:https://www.howie6879.com/post/2021/02_k8s_note_02_basic_concept/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
