nndl_note: 深度神经⽹络为何很难训练
上一章提到了神经网络的一种普遍性,比如说不管目标函数是怎样的,神经网络总是能够对任何可能的输入得到一个近似的输出。
普遍性告诉我们神经⽹络能计算任何函数;而实际经验依据提⽰深度⽹络最能适⽤于学习能够解决许多现实世界问题的函数
而且理论上我们只要一个隐藏层就可以计算任何函数,第一章我们就用如下的网络结构完成了一个手写字识别的模型:
这时候,大家心中可能都会有这样一个想法,如果加大网络的深度,模型的识别准确率是否会提高?

随即我们会基于反向传播的随机梯度下降来训练神经网络,但实际上这会产生一些问题,因为我们的深度神经网络并没有比浅层网络好很多。那么此处就引出了一个问题,为什么深度神经网络相对训练困难?
仔细研究会发现:
-
如果网络后面层学习状况好的时候,前面的层次经常会在训练时停滞不前
-
反之情况也会发生,前面层训练良好,后面停滞不前
实际上,我们发现在深度神经⽹络中使⽤基于梯度下降的学习⽅法本⾝存在着内在不稳定性,这种不稳定性使得先前或者后⾯神经网络层的学习过程阻滞。
消失的梯度问题
我们在第一章识别手写字曾经以MNIST数字分类问题做过示例,接下来我们同样通过这个样例来看看我们的神经网络在训练过程中究竟哪里出了问题。
简单回顾一下,之前我们的训练样本路径为/pylab/datasets/mnist.pkl.gz ,相关案例代码在pylab都可以找到(我稍做了改动以支持Python3)。
|
|
最终我们得到了分类的准确率为 96.47%,如果加深网络的层数会不会提升准确率呢?我们分别尝试一下几种情况:
|
|
这说明一种情况,尽管我们加深神经网络的层数以让其学到更复杂的分类函数,但是并没有带来更好的分类表现(但也没有变得更差)。
那么为什么会造成这种情况,这是我们接下来需要思考的问题。可以考虑先假设额外的隐藏层的确能够在原理上起到作⽤,问题是我们的学习算法没有发现正确地权值和偏置。
下图(基于[784, 30, 30, 10]网络)表⽰了每个神经元权重和偏置在神经⽹络学习时的变化速率,图中的每个神经元有⼀个条形统计图,表⽰这个神经元在⽹络进⾏学习时改变的速度。更⼤的条意味着更快的速度,而小的条则表⽰变化缓慢。
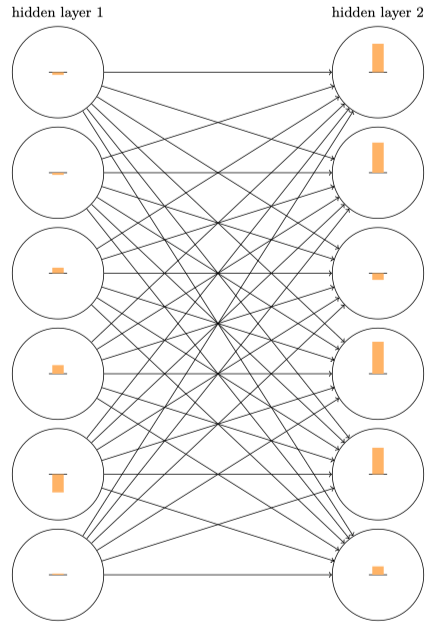
可以发现,第⼆个隐藏层上的条基本上都要⽐第⼀个隐藏层上的条要⼤;所以,在第⼆个隐藏层的神经元将学习得更加快速。这并不是巧合,前⾯的层学习速度确实低于后⾯的层。
我们可以继续观察学习速度的变化,下方分别是2~4个隐藏层的学习速度变化图:

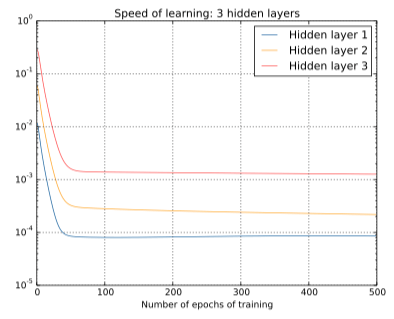
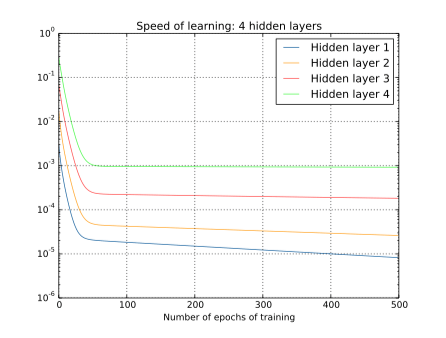
同样的情况出现了,前⾯的隐藏层的学习速度要低于后⾯的隐藏层。这⾥,第⼀层的学习速度和最后⼀层要差了两个数量级,也就是⽐第四层慢了 100 倍。
我们可以得出一个结果,在某些深度神经⽹络中,在我们隐藏层反向传播的时候梯度倾向于变小;这意味着在前⾯的隐藏层中的神经元学习速度要慢于后⾯的隐藏层,这个现象也被称作是消失的梯度问题。
导致梯度消失的原因
核心原因在于深度神经网络中的梯度不稳定性,会造成前面层中梯度消失或者梯度爆炸
看下面这个既简单的深度神经网络,每⼀层都只有⼀ 个单⼀的神经元:

首先回顾几个计算公式:
- 第$j$个神经元的输出:$a_j = \sigma(z_j)$ 其中$\sigma$就是
Sigmoid函数 - $z_j = w_j*a_{j-1}+b_j$
让我们通过公式追踪一下$b_1$的变化趋势: $$ \begin{aligned} \frac{\partial C}{\partial b_{1}} = \frac{\partial C}{\partial a_{4}} \times \frac{\partial a_{4}}{\partial z_{4}} \times \frac{\partial z_{4}}{\partial a_{3}} \times \frac{\partial a_{3}}{\partial z_{3}} \times \frac{\partial z_{3}}{\partial a_{2}} \times \frac{\partial a_{2}}{\partial z_{2}} \times \frac{\partial z_{2}}{\partial a_{1}} \times \frac{\partial a_{1}}{\partial z_{1}} \times \frac{\partial z_{1}}{\partial b_{1}} \end{aligned} $$ 以小见大一下,对于上述式子,可以做一下拆解:
-
$a_4 = \sigma(z_4) = \sigma(w_4*a_3 + b_4)$
-
$\frac{\partial a_4}{\partial z_4} = \frac{\partial \sigma(z_4)}{\partial z_4}=\sigma^{\prime}\left(z_4\right)$
-
$\frac{\partial \sigma(z_4)}{\partial a_3} = \frac{\partial \sigma(w_4*a_3 + b_4)}{\partial a_3} = w_4$
-
$\frac{\partial z_1}{\partial b_1} = \frac{\partial \sigma(w_1*a_0 + b_1)}{\partial b_1} = 1$
故:
$$
\begin{aligned}\frac{\partial C}{\partial b_{1}} = \frac{\partial C}{\partial a_{4}} \times \sigma^{\prime}(z_4) \times w_4 \times \sigma^{\prime}(z_3) \times w_3 \times \sigma^{\prime}(z_2) \times w_2 \times \sigma^{\prime}(z_1) \times 1
\end{aligned}
$$
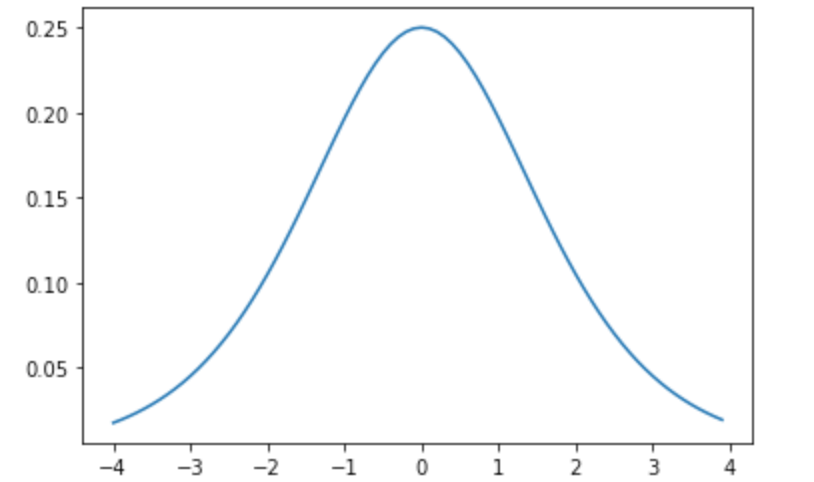
其实可以直观地看出上述表达式是一系列如$w_j\sigma^\prime(z_j)$的乘积,其中有sigmoid的导数,我们可以观察一下$\sigma^\prime(x)$的函数图像($\sigma^\prime(x) = \sigma(x)(1 - \sigma(x))$):
绘图代码:
|
|
结合上述公式和函数图像,我们可以得出以下结论:
- 由于权重一般是基于均值为0方差为1的高斯分布,所以任何权重总是处于$(0, 1)$
- $\sigma^\prime(x) \leq 0.25$
- $w_j\sigma^\prime(z_j)<0.25$
再结合上面的表达式,当层数越多,乘积项就会越多,就会导致$\frac{\partial C}{\partial b_{1}}$更小,于是就导致了梯度消失。
Sigmoid作为激活函数情况下,由于梯度反向传播中的连乘效应,导致了梯度消失
反之,梯度爆炸的问题就是神经网络前面层比后面层梯度变化快,从而引起了梯度爆炸的问题,比如$w$较大导致了$|w_j\sigma^\prime(z_j)|>1$,再结合上面提到的连乘效应,就自然地梯度爆炸了。
在更加复杂⽹络中的不稳定梯度
当我们从简单的神经网络上发现了随着网络层次的加深,会造成网络权值更新不稳定的情况后,也很明确地观察到了梯度消失问题。继续扩展一下,对于那些每层包含很多神经元的更加复杂的网络来说会是怎样的情况呢?
对于第$l$层的梯度: $$ \delta^{l}=\Sigma^{\prime}\left(z^{l}\right)\left(w^{l+1}\right)^{T} \Sigma^{\prime}\left(z^{l+1}\right)\left(w^{l+2}\right)^{T} \ldots \Sigma^{\prime}\left(z^{L}\right) \nabla_{a} C $$ 根据连乘效应,会导致出现不稳定的梯度,和前面例子一样,会导致前面层的梯度指数级地消失。
其它深度学习的障碍
前面三节主要介绍了一大障碍:不稳定梯度(梯度消失或者梯度爆炸),实际上,不稳定梯度仅仅是深度学习的众多障碍之⼀。
下面会据一些关于什么让训练深度⽹络⾮常困难相关主题的例子,这是个相当复杂的问题:
- 在 2010 年
Glorot && Bengio发现证据表明 sigmoid 函数的选择会导致训练⽹络的 问题。特别地,他们发现sigmoid函数会导致最终层上的激活函数在训练中会聚集在 0,这也导 致了学习的缓慢。他们的⼯作中提出了⼀些取代sigmoid函数的激活函数选择,使得不会被这种聚集性影响性能。 - 在 2013 年
Sutskever, Martens, Dahl 和 Hinton研究了深度学习使⽤随机权重初始化和基于momentum的SGD⽅法。两种情形下,好的选择可以获得较⼤的差异的训练效果。
论文地址:
- 原文作者:howie.hu
- 原文链接:https://www.howie6879.com/post/2020/02_why_are_deep_neural_networks_hard_to_train/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
