大学时期博文
1.问题
目前主流的搜索引擎,非google莫属,但其对于非法(流量异常、爬虫)请求的封锁也是异常严厉
本人前段时间有个脚本用到了谷歌搜索,具体见python之由公司名推算出公司官网(余弦相似度)当时直接使用的是一个python开源项目
但在使用过程中,单ip的情况下爬取速度可谓感人,稍不留神还会被封,所以对于获取谷歌搜索结果的爬虫有必要进行改进
说一说爬取谷歌搜索结果的问题:
- 1.正常打开谷歌搜索,然后审查元素想获取目标内容的时候,会发现是一大串js。
- 2.访问过快就会出现流量异常
2.如何解决
对于第一个问题:
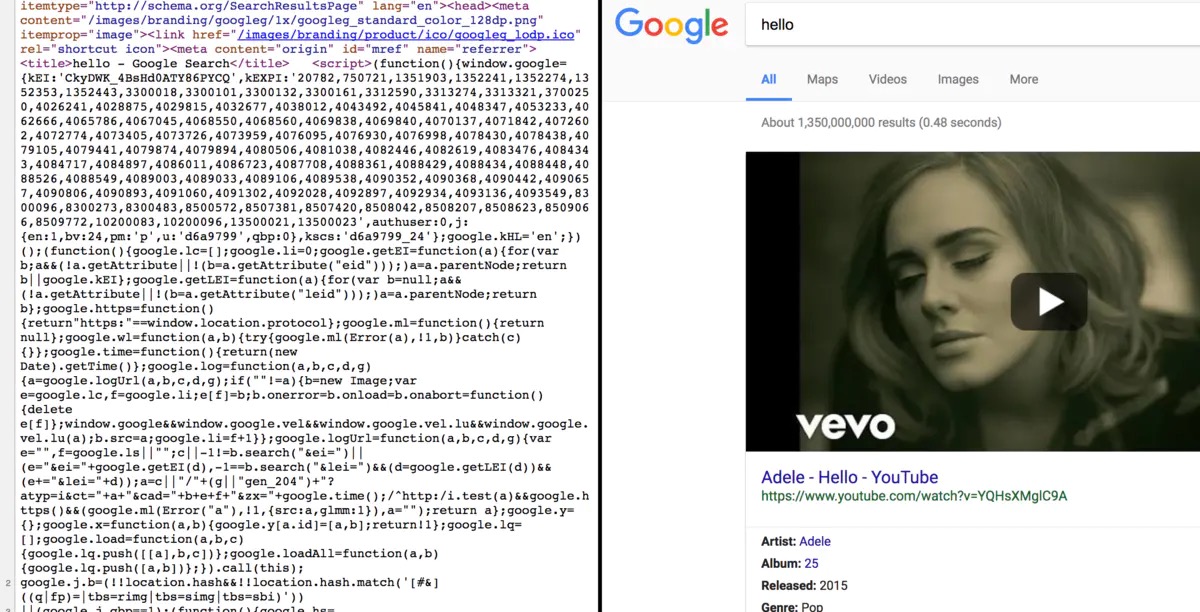
应该有看到审查元素出来的都是js,然后检索的url是这样的:
https://www.google.com.hk/search?q=hello&oq=hello&aqs=chrome..69i57j69i60l2j69i65j69i60j0.876j0j7&sourceid=chrome&ie=UTF-8&google_abuse=GOOGLE_ABUSE_EXEMPTION%3DID%3Daa946d8c657cf359:TM%3D1484917472:C%3Dr:IP%3D118.193.241.44-:S%3DAPGng0tGiKFaIr7YCaivUEmmEHOYJhG4jg%3B+path%3D/%3B+domain%3Dgoogle.com%3B+expires%3DFri,+20-Jan-2017+16:04:32+GMT
这里解决办法很粗暴,禁止掉js就好,让我们看看禁止js后是什么样的:
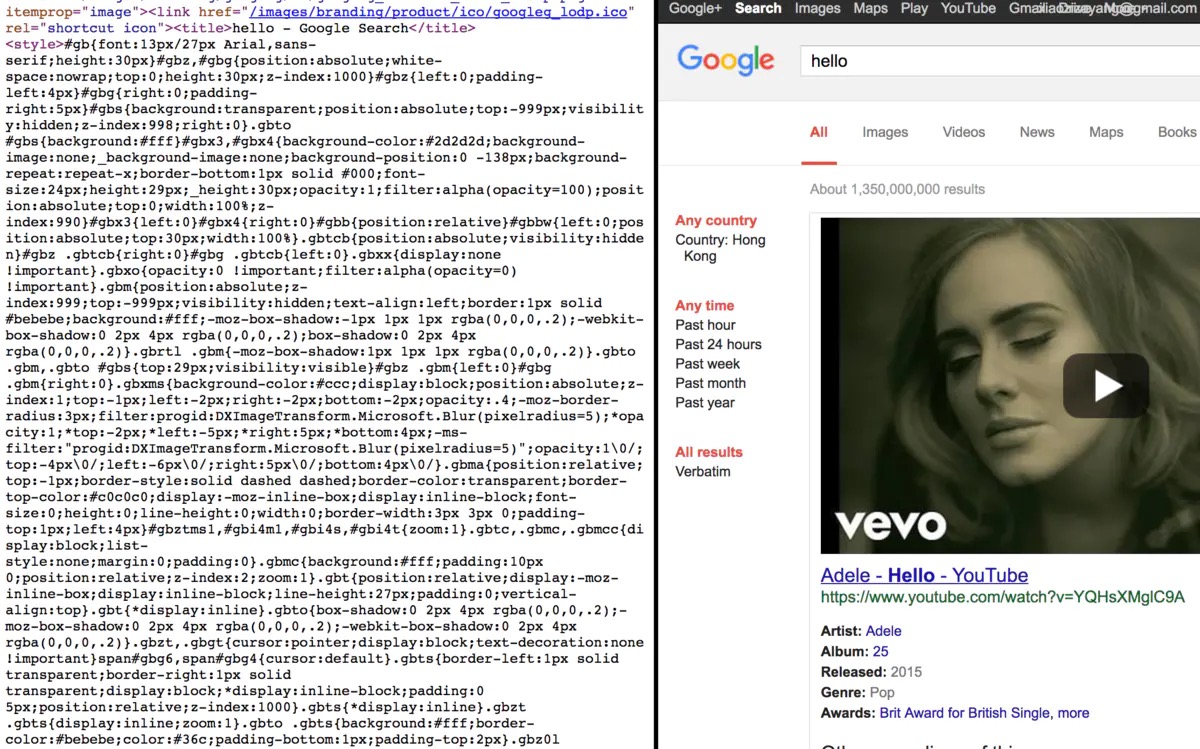
然后再看url:
1
|
https://www.google.com.hk/search?q=hello&btnG=Search&safe=active&gbv=1
|
对于这个url,相信机智的你应该会明白些什么,这里可以写个简单的脚本,比如说获取,谷歌搜索第一页所有结果的html,简单写下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
URL_SEARCH = "https://{domain}/search?hl={language}&q={query}&btnG=Search&gbv=1"
URL_NUM = "https://{domain}/search?hl={language}&q={query}&btnG=Search&gbv=1&num={num}"
def search_page(query, language='en', num=None, start=0, pause=2):
"""
Google search
:param query: Keyword
:param language: Language
:return: result
"""
time.sleep(pause)
domain = self.get_random_domain()
if num is None:
url = URL_SEARCH
url = url.format(
domain=domain, language=language, query=quote_plus(query))
else:
url = URL_NUM
url = url.format(
domain=domain, language=language, query=quote_plus(query), num=num)
try:
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
r = requests.get(url=url,
allow_redirects=False,
verify=False,
timeout=30)
charset = chardet.detect(r.content)
content = r.content.decode(charset['encoding'])
return content
except Exception as e:
logging.error(e)
return None
|
到了这里,问题才刚开始,你可以做个实验,我假设你是使用代理进行谷歌搜索,如果你连续不断无间隔使用谷歌搜索某一关键字二三十下,不出意外你会被要求进行这样的验证:

这个问题可真是让人十分厌恶,我并没有很好的解决办法,能做的唯有尽量避免:
1.ip轮询
2.每次结果爬取增加休眠
3.随机user_agent是必备
第一点和第三点不必多说,对于第二点增加休眠时间则需要我们好好地进行检测。
假设在单ip随机ua情况下:
- 1.这种情况下不休眠的话请求个两三次就会直接被封(第二天会被解封)
- 2.个人觉得这不是个解决办法,因为对休眠时间把控不好的话就会造成封ip,如果不想被封,我测试的话需要休眠60s浮动,这没什么意义
- 3.而且这种情况下发现是直接封ip,对开发者太不友好
对于这种情况,受同事神来一句,发现一个暂时的解决办法,请看下图:
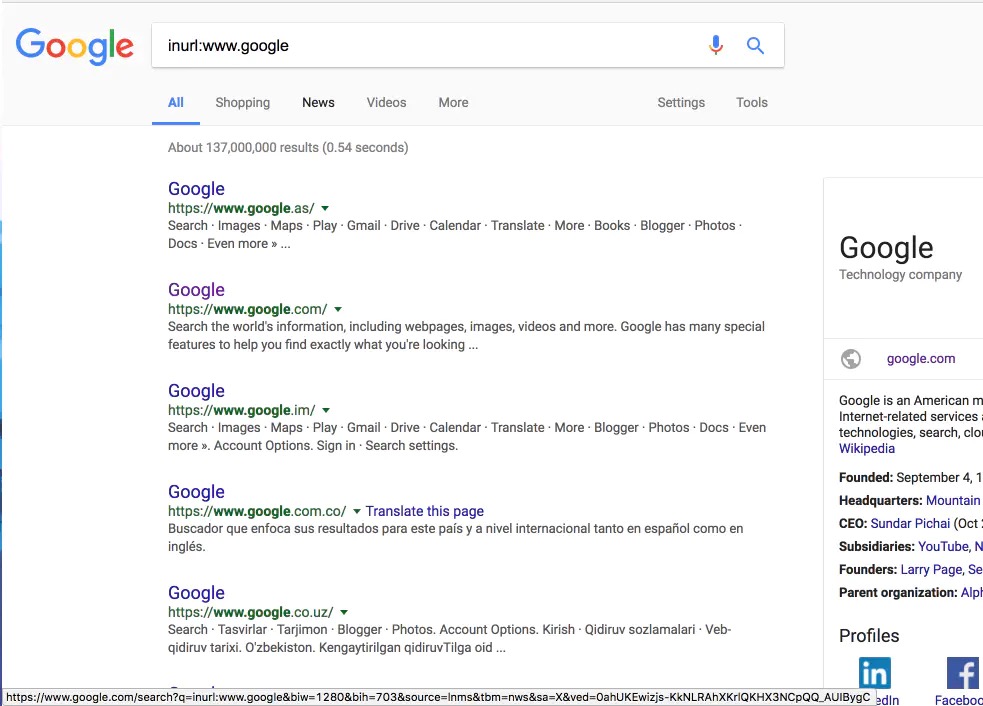
单一ip不停地访问统一谷歌域名自然很容易被察觉,谷歌全球190+的域名,难道都在实时的统计ip么,可能有,但绝对不会像单域名那样严格,来做个测试。
我将全球190+谷歌域名集中起来,像ua一样随机轮换,然后进行测试(单ip),结果还不错:
- 1.首先没有出现被封ip,只会提示流量异常
- 2.还是需要休眠,本人休眠5~15s没有被封过,可根据自身情况来,如果想稳妥点就5~30s吧
我将这些写成了一个项目,magic_google-python,若你是phper,可以看看我写的php版本php-google,具体代码可以看这里,对应的功能很简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
from magic_google import MagicGoogle
import pprint
# Or PROXIES = None
PROXIES = [{
'http': 'http://192.168.2.207:1080',
'https': 'http://192.168.2.207:1080'
}]
# Or MagicGoogle()
mg = MagicGoogle(PROXIES)
# Crawling the whole page
result = mg.search_page(query='python')
# Crawling url
for url in mg.search_url(query='python'):
pprint.pprint(url)
# Output
# 'https://www.python.org/'
# 'https://www.python.org/downloads/'
# 'https://www.python.org/about/gettingstarted/'
# 'https://docs.python.org/2/tutorial/'
# 'https://docs.python.org/'
# 'https://en.wikipedia.org/wiki/Python_(programming_language)'
# 'https://www.codecademy.com/courses/introduction-to-python-6WeG3/0?curriculum_id=4f89dab3d788890003000096'
# 'https://www.codecademy.com/learn/python'
# 'https://developers.google.com/edu/python/'
# 'https://learnpythonthehardway.org/book/'
# 'https://www.continuum.io/downloads'
# Get {'title','url','text'}
for i in mg.search(query='python', num=1):
pprint.pprint(i)
# Output
# {'text': 'The official home of the Python Programming Language.',
# 'title': 'Welcome to Python .org',
# 'url': 'https://www.python.org/'}
|
3.总结
对google搜索结果的爬取,有以下建议:
- 1.ip轮询
- 2.ua随机
- 3.domain随机
- 4.休眠
