1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
|
# -*-coding:utf-8-*-
__author__ = 'howie'
from urllib import parse
from bs4 import BeautifulSoup
from collections import defaultdict
import requests
import re
import nltk
import time
from config.webConfig import config
from CosineSimilarity import CosineSimilarity
from search.yahooSearch import yahooSearch
from search.gooSearch import search, searchWeb
class Website(object):
"""
通过公司名等信息获取网站官网
"""
def __init__(self, engine='google'):
self.forbid_www = config["forbid_www"]
self.forbid = config["forbid"]
self.engine = engine
def get_web(self, query, address=""):
"""
获取域名
:param query: 搜索词
:param address: 在此加上地址时,query最好是公司名
:return: 返回最可能是官网的网站
"""
if self.engine == 'google' and address:
allQuery = query + " " + address
result = searchWeb(query=allQuery, num=5)
if result:
return result
allDomain = self.get_domain(query)
if len(allDomain) == "1":
website = allDomain[0]
else:
# 初步判断网站域名
counts = self.get_counts(allDomain)
largest = max(zip(counts.values(), counts.keys()))
if largest[0] > len(allDomain) / 2:
website = largest[1]
else:
# 获取对应域名标题
domainData = self.get_title(set(allDomain))
# 计算相似度
initQuery = nltk.word_tokenize(query.lower(), language='english')
# 余弦相似性计算相似度
cos = CosineSimilarity(initQuery, domainData)
wordVector = cos.create_vector()
resultDic = cos.calculate(wordVector)
website = cos.get_website(resultDic)
return website
def get_domain(self, query):
"""
获取谷歌搜索后的域名
:param query:搜索条件
:return:域名列表
"""
allDomain = []
if self.engine == "google":
for url in search(query, num=5, stop=1):
allDomain += self.parse_url(url)
elif self.engine == "yahoo":
for url in yahooSearch(query):
allDomain += self.parse_url(url)
if not allDomain:
allDomain.append('')
return allDomain
def parse_url(self, url):
allDomain = []
domainParse = parse.urlparse(url)
# 英文网站获取
if "en" in domainParse[2].lower().split('/'):
domain = domainParse[1] + "/en"
else:
domain = domainParse[1]
domainList = domain.split('.')
# 排除干扰网站
if len(domainList) >= 3 and domainList[0] != "www":
isUrl = ".".join(domain.split('.')[-2:])
if isUrl not in self.forbid:
allDomain.append(domainParse[0] + "://" + isUrl)
elif domain not in self.forbid_www:
allDomain.append(domainParse[0] + "://" + domain)
return allDomain
def get_title(self, setDomain):
"""
获取对应网站title,并进行分词
:param allDomain: 网站集合
:return: 网站:title分词结果
"""
domainData = {}
for domain in setDomain:
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4",
"Cache-Control": "max-age=0",
"Proxy-Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36",
}
try:
data = requests.get(domain, headers=headers).text
soup = BeautifulSoup(data, 'html.parser')
title = soup.title.get_text()
title = re.sub(r'\r\n', '', title.strip())
titleToken = nltk.word_tokenize(title.lower(), language='english')
domainData[domain] = titleToken
except:
pass
return domainData
def get_counts(self, allDomain):
"""
返回网站列表各个域名数量
:param allDomain: 网站列表
:return: 网站:数量
"""
counts = defaultdict(int)
for eachDomain in allDomain:
counts[eachDomain] += 1
return counts
if __name__ == '__main__':
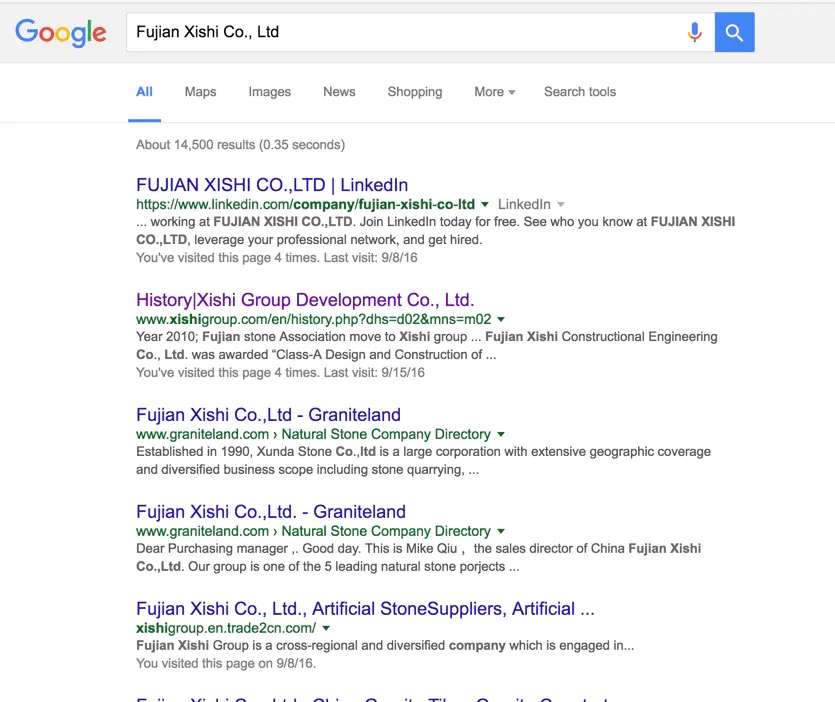
# allQuery = ["National Sales Company, Inc.", "Decor Music Inc.","Fujian Xishi Co., Ltd","Kiho USA Inc.","BusinessPartner Co.,ltd","BENKAI Co.,Ltd"]
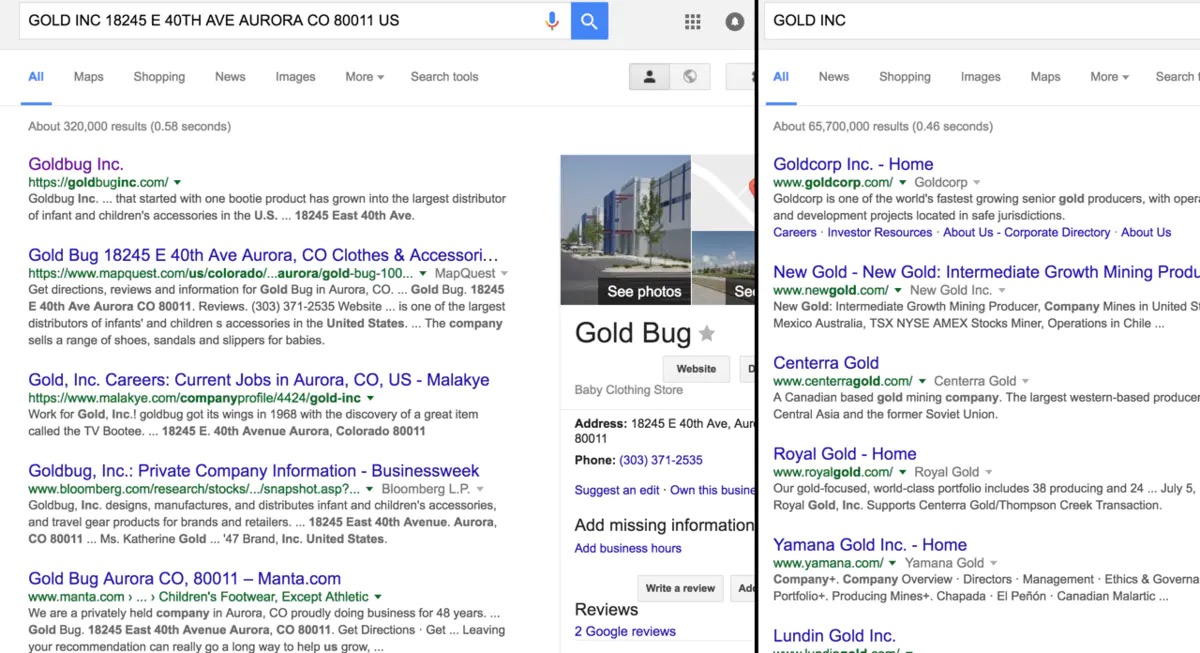
# GOLD INC 18245 E 40TH AVE AURORA CO 80011 US
allQuery = ["ALZARKI INTERNATIONAL"]
website = Website(engine='google')
for query in allQuery:
time.sleep(2)
website = website.get_web(query=query)
print(website)
|